The Grand Unification Theory of AI Infrastructure: Part II
Note: 本文是借助 AI 翻译的 VAST Blog,作者是 VAST Data 的联合创始人 Jeff Denworth。原文请见:The Grand Unification Theory of AI Infrastructure: Part II.
在 2023 年,我提出了 VAST 应该整合整个数据栈的理由,并说明了一种全新的架构能够实现这种宏大整合,而且不会对 AI 和传统应用带来任何妥协。事实上,这种新架构不仅仅是维持现状,它还能解决传统“点式解决方案”带来的瓶颈问题,并在规模、并行性、效率和弹性上释放新的潜力,同时支持大规模的整合。这个名字就是——VAST 数据平台(The VAST Data Platform)。
2023 年是训练之年,也是 VAST 真正开始在 AI 领域大展拳脚的一年。VAST 的客户已经部署了数十个 EB(艾字节)级的基础设施,用于训练最大规模的前沿模型。他们如今不仅在 VAST DataStore 中存储了海量的非结构化数据,还在 VAST DataBase 中存储了海量的上下文信息作为元数据。
一切都在加速。AI 的发展速度在不断提升,模型构建者们相互借鉴彼此的成果,并持续突破边界。虽然我们早在 2022 年初就开始谈论“会思考的机器”,但在过去 12 个月中推理模型的出现,意味着“思考机器”的时代已经真正到来。
这种变化的速度不仅体现在 AI 开发者身上。如今,我们接触到的每一家前瞻性客户都在竞相将其业务的核心逻辑转变为“智能体化”。这并不是夸大其词——我们看到投行正在努力实现员工效率提升 4 倍;企业们也在讨论部署数百万甚至上亿个 AI 智能体,以辅助并加速员工的工作。
于是,新的应用正在涌现,我们也拥有了极其强大的 AI GPU 硬件来驱动它们……问题是,我们如何让这一切变得足够简单、足够可扩展,从而让每一个组织都能踏上“智能体计算”的旅程?
另一方面,我们来看 VAST Data。自从 2023 年推出 VAST 数据平台以来,我们一直觉得这个称呼多少有些局限。为什么呢?
-
数据平台(Data Platforms)最初诞生于商业智能(BI)领域,但它们从未真正解决非结构化数据或深度学习的问题,而这些正是 VAST 深度优化的方向。事实胜于雄辩……GPU 厂商在训练或推理时并不会推荐使用 BI 工具,但他们会推荐 VAST。
-
数据平台在历史上往往部署在公有云上,因此错失了在底层基础设施层面挖掘效率提升的机会,而 VAST 则通过全新的硬件管理方式发现了这些关键的优化空间。传统数据平台在某种意义上,只是被动地接受了云厂商基于二十年前基础设施决策所强加的概念。相比之下,VAST 从 2016 年才开始架构设计,完全从一张白纸出发,并专注于新的底层硬件技术,最终为 AI 时代构建了一种现代化的“解耦共享一切”(DASE, Disaggregated, Shared Everything)架构。如今,DASE 已经成为大多数 GPU 云在处理数据时的核心基础,它具备足够的规模和效率,可以轻松支撑价值数十亿美元的算力集群。
-
数据平台过去也从未被视为一种能够支撑实时业务运行的系统。而在我们看来,这是一个致命缺陷,因为随着智能体化工作流不断向业务“前端”推进,实时性变得至关重要。即便如今市场上出现了“AI 数据平台”这一说法,但这种平台本质上仍然是运行在企业存储之上的一组批处理元数据服务,只是让存储能够被 AI 流水线访问而已……然而,AI 数据平台从未被设想为业务核心逻辑的基础设施。为什么?因为传统架构从未为可扩展的实时事务而设计,数据的采集、语境化和分析始终是基于批处理思维来完成的。客户甚至都不会去设想:在实时场景下能将海量数据与 AI 结合处理。原因是什么?架构。直到今天,一切能够扩展的系统几乎都是依赖于将数据集拆分到大型集群中。但数据分区会在规模化事务处理中带来延迟,因为集群需要维持一致性,而随着规模增长,东西向通信(节点间通信)过于庞大,进一步拖慢了速度。
简而言之,传统的存储与数据库系统根本不是为这种实时综合而设计的……结果就是,AI 发展受到限制。
那么问题来了,如果“数据平台”这个词会让人走偏,产生错误的认知,我们该如何把这一切真正统一起来?我们又该如何创造一个环境,让智能体能够存在并协作,在实时场景中进行发现和行动?同时,我们又如何让每个组织都能轻松利用这一全新的应用范式,并简便地使用眼前正在发生的计算硬件革命?
让我们来谈谈操作系统。
几十年来,正是操作系统让开发者和 IT 用户能够更方便地从底层硬件中获取价值。从桌面时代(个人电脑),到移动时代(智能手机),再到云计算时代(云数据中心),每一次计算革命都伴随着新的应用栈(办公效率、移动互联、大数据),而这些应用栈的实现,都是建立在新的设备平台之上的。
什么是操作系统?在智能体时代,我们又该如何理解其需求?
它包含以下几个关键组成部分:
- 一组设备驱动程序,用于管理硬件
- 一个存储环境,用于保存数据,并通过索引帮助快速定位数据
- 一个具备调度器的运行时环境,用于运行应用程序
- 一个消息系统,使应用程序能够通过通用 API 相互通信
当我们思考 VAST 正在打造的是什么时,我们回想起自己在 2016 年为公司设立的“思考机器”这一北极星愿景。随后我们意识到,用“操作系统”来定义 VAST 在 AI 时代所提供的能力,是最恰当的。让我们来看一看:
- 我们从硬件层出发,向上构建……实现艾字节级别的扩展,以及无限并行处理的规模
- VAST DataSpace 将这一硬件环境向外扩展,实现全球范围内的存储与计算联邦化
- VAST DataStore 是承载来自现实世界丰富数据的目的地
- VAST DataBase 是存放海量元数据的目录,支持大规模实时写入与表格和向量的查询
- VAST DataEngine 是负责触发和编排 AI 工作负载的计算框架
- VAST InsightEngine 是运行在 DataEngine 内的数据精炼工厂,借助 AI 嵌入模型将原始的非结构化数据转化为语境信息,并将其作为 RAG(检索增强生成)工具提供使用
本质上,你已经拥有了操作系统的所有核心组成部分,而且每一个都被设计成能够满足运行最具规模化的实时 AI 流水线所需的扩展性、性能和效率。我们构建了一套统一的、单体化的软件栈,它大幅降低了基础设施的复杂度,避免了解决方案的四处分散,涵盖了一切……除了智能体本身——直到今天。
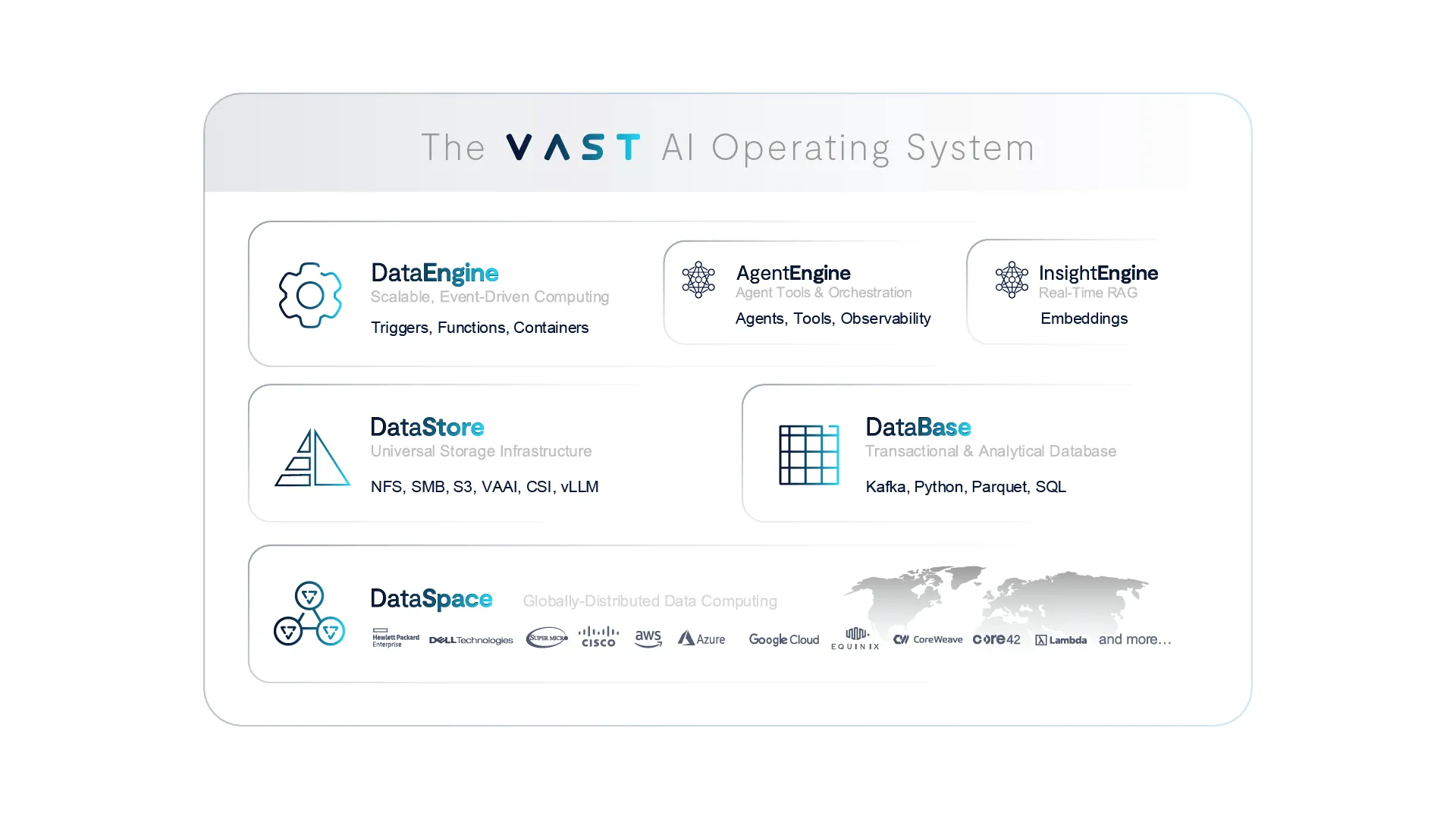
今天,我们正式揭晓一套全新的 AI 智能体部署与编排系统,它原生运行在 VAST DataEngine 之内,被称为 VAST AgentEngine。AgentEngine 是一个低代码的智能体部署与编排系统,配备了所有 MCP 兼容工具,能够为智能体提供所需的能力,同时还内置了一个功能丰富的可观测性平台,帮助开发者监控、管理和治理 AI 流水线。该解决方案将在 2025 年下半年正式发布,旨在让用户能够轻松定义智能体,将其与推理模型配对,并在 VAST 平台上实现自动化扩展。
AgentEngine 是拼图的最后一块,它完善了我们认为运行智能体应用所必需的核心服务。至此,我们的产品进入了演进的下一个阶段——向大家介绍 VAST AI 操作系统。
我们不仅推出了一套面向 AI 智能体的完整操作系统,还将提供一些示例智能体,作为开源参考,帮助客户在构建之路上加速前进。我们把这比作微软发布 Windows 时附带的“扫雷”游戏。扫雷让人们体会到新计算平台的用法和威力……因此我们也会推出属于自己的“扫雷”。
从今年开始,我们将每个月发布一个新的开源 AI 智能体,用以展示智能体的强大能力。视频编辑、销售策略师、科学研究员、数据工程师、金融分析师、合规经理……这些智能体有的会针对特定行业深度定制,有的则会是简单的助手,帮助 IT 团队更好地管理运维工作。
应用 + 运行时 + 基础设施。这就是一个操作系统……而且是一个非常强大的操作系统。
你上一次为存储阵列购买 RAID 控制器是什么时候?15 年前?时代在发展,当产品变得更强大、更全面时,点式解决方案就逐渐淡出人们的视野,就像如今普通人已经不需要再去单独购买 RAID 控制器或 MIDI 设备驱动一样。
早在 2016 年,我们发布过一段视频,其中提出了一个理念:“通过简化来实现扩展”。在 VAST,我们坚信,要实现最大化的潜在收益,关键在于简化和减少那些必须解决的基础性难题。如果我们能够提供一种简单的方法,几乎涵盖 AI 所需的全部基础设施层,而且没有妥协……客户就能获得巨大的收益。
几十年来,客户已经习惯于集成无数基础设施解决方案和服务来搭建他们的应用体系。随便看看一个标准的 AWS 蓝图,你就会发现需要拼接 10 到 30 个服务才能构建出一条完整的计算流水线。为什么会这样?因为从未有一个系统能够在所有维度上都提供最优能力……直到 VAST 出现。我们的架构不仅让我们能够在众多不同的应用场景中积极竞争,还带来了一套简单而统一的解决方案,专为深度学习时代而生。客户如今也逐渐认识到,这才是确保 AI 随时可用的关键。
在许多情况下,VAST 带来的创新不仅能够实现大规模的基础设施整合与简化,还让许多传统的计算方式变得不再相关。我在博客中很少点名竞争对手……部分原因是我们的产品本身没有真正的对标对象。但随着我们进入更抽象的层面(操作系统),我认为有必要指出一些将在我们的 AI 操作系统被采用后受到颠覆的产品类别及相关产品。
| Category | Incumbent Players Being Disrupted or Made Obsolete | On-Prem Examples | Cloud Examples |
|---|---|---|---|
| File Storage | NetApp • Dell PowerScale • Pure FlashBlade • Lustre • IBM GPFS | NetApp • Dell PowerScale • Pure FlashBlade • Lustre • IBM GPFS | AWS EFS • NetApp 等 |
| Object Storage | Dell ECS • NetApp StorageGrid | Dell ECS • NetApp StorageGrid | AWS S3 • Azure Blob 等 |
| Block Storage | Pure FlashArray • Dell PowerStore • NetApp • HPE Alletra | Pure FlashArray • Dell PowerStore • NetApp • HPE Alletra | AWS EBS • Google Hyperdrive 等 |
| Event Platform | Confluent Kafka • RedPanda | Confluent Kafka • RedPanda | Confluent • AWS Kinesis • GCP Pub/Sub 等 |
| Data Warehouse | Cloudera • Oracle Exadata • Vertica | Cloudera • Oracle Exadata • Vertica | Snowflake • Databricks • EMR • Fabric 等 |
| Vector Database | Pinecone • Milvus • pg-vector • QDrant | Pinecone • Milvus • pg-vector • QDrant | AWS OpenSearch • Azure AI Search 等 |
| Containers | RedHat • VMWare • Nutanix | RedHat • VMWare • Nutanix | AWS EKS • Google GKE • Azure AKS |
| Runtime | Knative • Cloudera | Knative • Cloudera | Vertex • Bedrock • Databricks • Snowflake 等 |
DASE 是我们的不对称优势,它释放了 AI 操作系统的潜力,并让我们在各个领域都具备竞争力。系统的多样化能力进一步将我们与其他方案区分开来,因为它统一了数据管理与安全,同时把多模态的传统计算与 AI 计算直接带到数据身边。
总体而言,有数千亿美元规模的基础设施正等待被颠覆和现代化。随着我们逐步将愿景推向市场,我们预见到 VAST 的架构和计算模式将使客户在未来不再需要某些完整的技术类别:
谁还需要分层存储,当闪存的成本正在逼近磁带?没有人需要。
谁还需要独立的块存储和文件存储?没有人需要。
谁还需要事件总线,当数据仓库本身就可以处理事务?没有人需要。
谁还需要单独的向量数据库,当向量可以直接嵌入原始数据?没有人需要。
这些例子说明了为什么我们认为 VAST 是“类别的终结者”,而不是“单一品类的颠覆者”。VAST 的真正超能力之一,就是它根本不在意市场如何对产品进行分类。20 年后,当我们回望今天的技术时,一定会疑惑:为什么当时一切要弄得这么复杂?我们所做的,只是努力为客户找到正确的方向,从最根本的层面去解决问题,然后创新自然随之而来。
所以,欢迎来到 VAST 的新时代——AI 操作系统的时代。
Enjoy Reading This Article?
Here are some more articles you might like to read next: