White Paper: The VAST DataStore
Note: 本文是借助 AI 翻译的 VAST 白皮书,原文请见:The VAST DataStore.
存储,也就是可靠地存储和读取数据的基本能力,是任何数据处理系统的基石,因此 VAST DataStore 构成了整个 VAST Data Platform 的核心基础。毕竟,任何数据平台的首要任务就是保存数据。
VAST DataStore 提供了 VAST Data Platform 的“持久性层”和“数据服务层”。通俗来说,VAST DataStore 负责在整个平台中通过标准的数据访问协议(如文件、对象和块存储)来存储、保护、加密并提供数据访问服务,从而为平台上的各种应用和工作负载提供统一的数据存储能力(即 Universal Storage)。
Designing the VAST DataStore
在 VAST 出现之前,整个计算行业普遍认为,要高效存储数据,就必须依赖多层次的存储架构,每一层都有其特定的性价比定位。存储厂商构建、用户采购的存储系统,往往都是为了满足这种“存储金字塔”中的某一层或几层需求。全闪存系统速度快,但容量小且价格昂贵;而共享无状态(shared-nothing)架构虽然具备良好的扩展性,却难以处理小文件,也难以实现 1 毫秒以内的延迟。
为了让 VAST DataStore 实现真正的“统一存储”(Universal Storage),我们必须打破传统架构中的各种权衡与限制。这套系统不仅要能扩展到支持训练先进 AI 模型所需的 EB(百亿 GB)级数据规模,还要保持毫秒级甚至亚毫秒级的低延迟,并达到企业用户对全闪存阵列所期待的“5 个 9”(99.999%)高可用性。它还必须支持来自成千上万客户端的并行 I/O,并提供强一致性,以支撑事务型应用。更关键的是,这一切还要在用户按 PB(千万 GB)级别采购时具备合理的成本。
VAST DataStore 是一套将 CNode 与 SSD 组成的 DASE 集群整合为统一存储系统的软件与元数据结构。它支持多种应用和数据类型,包括块设备(volumes)、文件和表格数据。通过专门为共享的持久性 SCM(存储级内存)SSD 优化的元数据结构,VAST DataStore 能充分利用集群中每个 CNode 与每块 SSD 之间的低延迟直连能力。
与早期仅在小容量范围内提供低延迟的全闪存阵列不同,VAST DataStore 从设计之初就旨在高效管理从 PB 到 EB 级别的数据。这不仅仅意味着通过纠删码和数据压缩等技术提升容量利用率,更意味着它还要实现对闪存寿命的高效管理与优化。
VAST DataStore 通过两个子层来管理数据:
物理层(或称块管理层) 负责对小数据块(平均大小为 32KB)提供基本的数据持久化服务,这些小块正是 VAST Element Store 所使用的原子存储单位。该层包含诸如纠删码(erasure-coding)、数据分布、数据压缩(data reduction)、闪存管理以及静态数据加密(encryption at rest)等关键功能,用以保障数据的可靠性、安全性与存储效率。
VAST Element Store 则是在上一层基础上,进一步将这些受保护的原子单元组织成更高级别的数据结构,如文件、对象、表格(tables)和逻辑卷(LUNs)。这一层为用户提供对这些数据元素的协议级访问,同时支持基于元素或路径的高级功能,比如快照(snapshots)、克隆(clones)、复制(replication)等,并包括 VAST 的 Constellation 全球命名空间功能,确保跨地域和多节点环境下的数据一致性与统一访问。
这两个层次协同工作,共同构建了一个新一代的数据存储系统,其核心设计目标包括:
-
在提供全闪存性能的同时扩展到 EB 级别容量,并具备接近机械硬盘的经济性。也就是说,系统既要快,又要大,还要便宜。
-
提供统一命名空间,原生支持多种数据类型,包括文件、对象、块存储卷(block volumes)和表格数据,无需借助网关或协议转换,大大简化了系统架构和运维复杂度。
-
提供完整的数据服务功能,包括零开销写入的快照(zero-write snapshots)和灵活的数据复制机制,满足备份、容灾、跨站点同步等多样需求。
-
以 VAST 提供的 SCM(存储级内存)作为系统状态和元数据的“单一真实来源”,确保整个系统的强一致性与快速响应能力。
-
在数据和元数据更新过程中提供严格的 ACID 一致性保障,满足高可靠场景下的事务处理需求。
-
通过智能预测与写入调控(write shaping)减少闪存磨损,延长设备寿命,降低维护成本。
-
实现最高级别的容错能力(n+4 冗余)且开销低于 3%,打破了传统上性能、效率和成本三者之间必须取舍的局限。
需要注意的是,本文所描述的“分层结构”并不意味着系统内部存在严格的边界。物理层与 Element Store 层实际上共享许多元数据结构,某些系统任务或数据服务甚至跨越了这两层的逻辑边界。这种“层级模糊性”在处理“表格类型元素”(tables)时尤为明显:虽然这类数据由 VAST DataStore 存储,但其管理与访问则通过 VAST DataBase 实现。这反映了系统底层高度融合与灵活的架构设计。
Defining the DataStore
A New Approach to Metadata
虽然这样说可能稍显简单化,但你可以把 VAST Element Store 理解为一个“超级文件系统”。它能够同等自如地呈现文件、表格、卷、事件触发器、函数和对象等多种数据形式。VAST Element Store 与物理层之间通过面向字节的元数据紧密耦合。
尽管常被忽略,但现代存储系统的许多关键特性实际上都依赖于元数据。这些特性包括精简配置(thin provisioning)、快照、克隆以及数据去重等。我们已经多次看到,一个存储系统在最初设计阶段所作出的数据布局和元数据结构决策,往往会深远影响它后续能否支持丰富的功能。
任何数据存储系统最重要的任务,都是保持数据视图的一致性——确保用户或应用在发出读取请求时,始终能获取“该获取”的数据。虽然某些场景下“最终一致性”已足够使用,但真正的数据处理系统则需要严格的一致性。在进一步探讨 VAST DataStore 是如何组织数据之前,我们先来看看它是如何保障这种一致性的。
Inherently Persistent
VAST DataStore 的所有元数据——从基础的文件名,到多协议访问控制列表(ACLs)与锁信息——都保存在 VAST 机箱中的共享介质上。这种方式使得经过镜像和分布的元数据可以作为 Element Store 状态的唯一真实来源,确保系统状态的一致性。
通过取消服务器端缓存,VAST 不仅消除了保持多个存储控制器之间缓存一致性的开销和复杂性,还简化了整个系统架构。VAST 系统将全部系统状态数据存储在共享机箱中,并通过 NVMe-oF 实现所有服务器的全局访问。由于每个 VAST 服务器都可以直接访问这唯一的系统状态源,因此不需要像传统“共享无状态”架构那样,在节点之间频繁交换信息来同步缓存状态。这种架构带来两个关键优势:
首先,VAST 使用的存储级内存(Storage Class Memory,SCM)具有天然的持久性,无需依赖 DRAM 或 NVRAM 作为缓存。因此,不会存在从易失性缓存中“退役(destage)数据”的问题。而在传统企业存储中,数据丢失往往就源于缓存管理或退役失败这一环节,因为这些操作本身非常复杂。而 VAST 则彻底规避了这一风险——即便在支持大规模、高效率写入条带(write stripe)的情况下也不例外。而且因为没有缓存,自然也不再需要电池或超电容器等掉电保护机制,这也降低了硬件维护的复杂性与成本。
其次,由于无需进行缓存协调,VAST 能够更加轻松地扩展 I/O 服务能力。其架构在同步读写路径中完全消除了节点间横向通信(即“东西向通信”)的需求,从而避免了许多需要跨集群协调的操作(如元数据更新、锁管理等)。当你在集群中增加更多服务器 CPU 时,系统性能将呈现线性增长;而在传统架构中,由于全局操作需在多个节点间协调,往往会遭遇“收益递减”的瓶颈。
Transactionally Consistent
在设计 VAST DataStore 时,我们的目标不仅是支持文件和对象,还要能承载表格数据。因此,我们必须将 ACID 数据库的事务保障,与并行文件系统的性能和对象存储的扩展性有机融合。为了实现这一目标,VAST Data 构建了一种全新的分布式事务模型,采用混合元数据结构,将一致性哈希(consistent hashing)与树形结构元数据(tree-oriented metadata)相结合,并结合了受日志机制启发的“自由空间写入”数据布局、全新的锁机制与事务管理技术。
VAST DataStore 的核心在于:它在一组共享的存储级内存(SCM)池中管理元数据,每个数据元素(包括文件、对象、文件夹、表格、卷等)都拥有一个自己的 V-Tree 结构来记录其元数据。系统通过将每个元素的唯一标识符(handle)进行一致性哈希,从而定位其对应 V-Tree 的根节点。哈希空间被划分为多个范围(range),每个范围由集群中两台机箱(enclosure)共同负责。这两台称为 DBox 的设备会保存其负责范围内所有元素的元数据根节点。
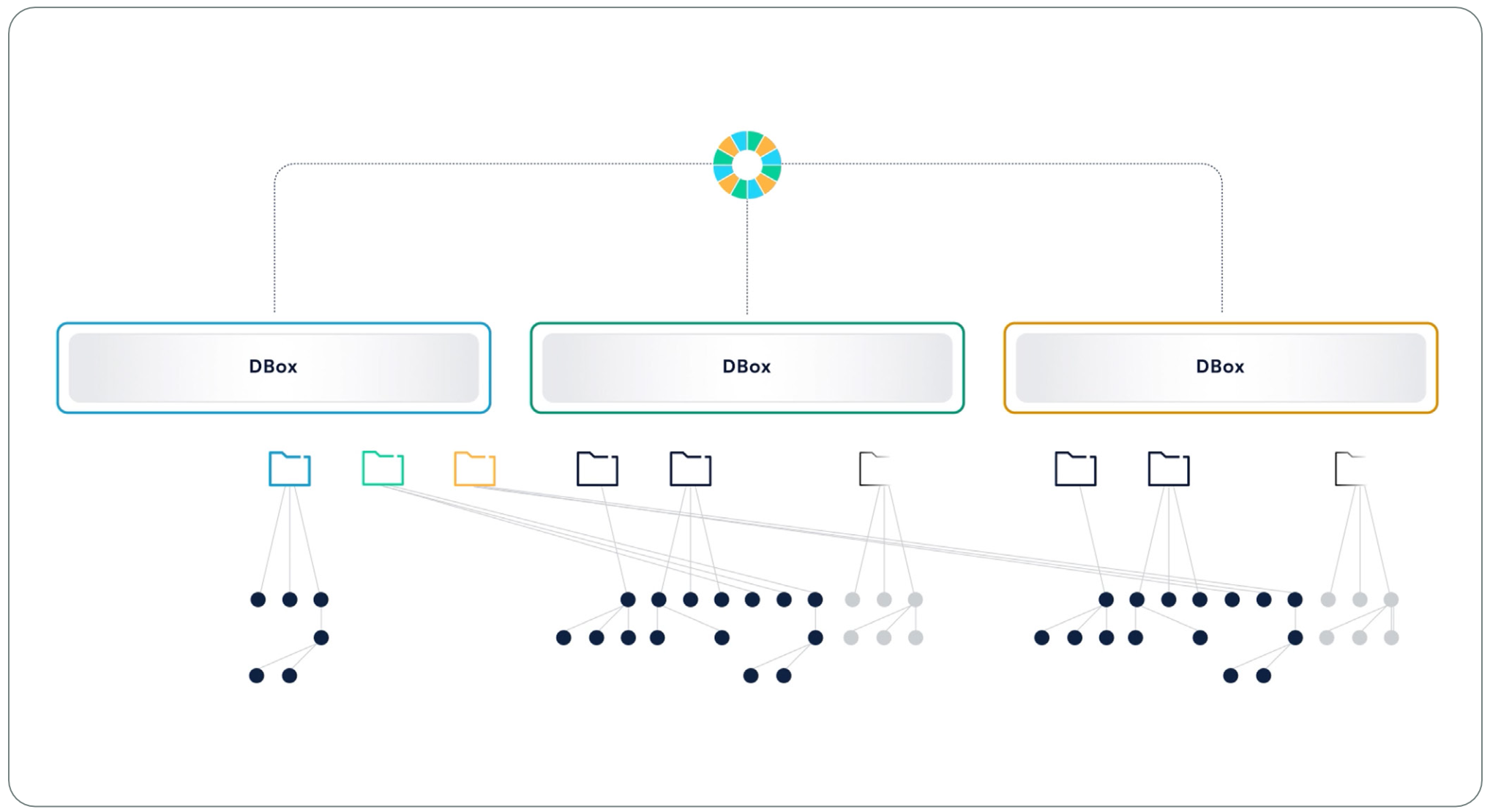
在系统启动时,所有 VAST 服务器都会将一个大小为 1GB 的一致性哈希表加载进内存。当服务器需要访问某个文件或对象中的数据时,它会对该元素的 handle 进行哈希计算,并在内存中高速查找其属于哪个哈希范围,从而迅速定位出负责该元素元数据的 DBox,然后从中读取该元素的 V-Tree。
VAST 系统通过仅将一致性哈希用于数据元素根节点的定位,极大降低了每个哈希表所需处理的数据量。即使集群规模扩大,系统也只需要重新分配极少量的哈希数据,避免了大规模的重新平衡。当新的机箱(enclosure)加入集群时,它只需“接管”自己负责的哈希区间,并迁移该区间内的元数据,整个过程快速且资源开销极小,从而实现平滑扩展。
V-Trees for Fast Access
VAST DataStore 通过一种名为 V-Tree 的结构来维护其持久化元数据。V-Tree 是一种改良版的 B 树结构,专门为部署在共享的持久性内存中而设计。由于 VAST 服务器本身是无状态的,为了让它们能够高效地遍历存储在远端 SCM(存储级内存)设备上的元数据,VAST 设计了一种具有超宽分支结构的树形系统:每个节点可以拥有数百个子节点,从而减少查找路径的深度,使一次完整的查找过程最多只需七次网络往返即可完成。
VAST 服务器本身不保留任何本地状态,这种无状态设计使得系统具备良好的可扩展性和容错能力。当新服务器加入集群时,它通过一致性哈希算法定位需要处理的元数据树的根节点。而随着更多服务器资源的加入,集群中的主节点会自动对任务责任进行再平衡。如果某台服务器发生故障,其他服务器可以快速接管其虚拟 IP(VIP),客户端在常规超时重试范围内即可自动连接到新的服务器,保障服务不中断。
虽然 VAST DataStore 并不像传统数据库那样以“表格、行、列”组织数据,但其 V-Tree 架构赋予了它类似数据库的查询能力。借助这一结构,VAST 服务器可以并行查询元数据,比如在一个 S3 桶中定位某个对象,或者回溯查看某个文件在 2024 年 1 月 1 日凌晨 12:01 时刻快照中的状态。
就像增加 CPU 可以线性提升计算能力一样,DataStore 的元数据也分布在整个集群的所有 SCM 中。这种架构不仅实现了命名空间的横向扩展,也确保了系统性能能够随集群规模扩大而线性提升。
Database Semantics
VAST DataStore 的命名空间元数据在某种程度上可以看作是一个数据库,系统通过它进行查询,以根据文件名、对象名、快照时间或其他元数据属性来定位具体的数据位置。这种“数据库类比”也体现在其事务机制上:VAST DataStore 采用了与关系型数据库类似的事务语义,实现了完整的 ACID 保证(原子性、一致性、隔离性和持久性)。
不同于那些采用“最终一致性”的系统(如传统对象存储),VAST DataStore 提供的是一个全局一致的命名空间,对集群中所有 VAST 服务器及其用户而言都是统一一致的。当一个用户在某个节点上进行更改后,该更改会立即在集群中其他所有节点和用户中可见。
为了保持这种一致性,VAST DataStore 确保每一个事务都具备原子性。这意味着每一次存储事务要么完整地作用于所有相关元数据及其镜像,要么完全不生效,即使该事务涉及多个元数据对象的更新,也不会出现部分成功、部分失败的情况。正是由于这种原子写一致性,VAST 系统无需依赖传统文件系统中的一致性检查工具(如著名的 fsck),即便在断电后重新上电,也能立即恢复功能、保持系统一致性。
Transaction Tokens
VAST 的 V-Tree 更新事务通过一种名为“事务令牌(transaction tokens)”的机制进行管理。当某个 VAST 服务器发起事务时,它会创建一个对应的事务令牌元数据对象,并递增事务令牌计数器。每个事务令牌都包含一个全局唯一标识符,所有 VAST 服务器都可以访问它,用于追踪跨多个元数据对象的更新过程。该令牌中还嵌入了事务发起服务器的身份信息以及事务当前的状态(进行中、已取消、已提交),以便系统在并发操作场景下进行正确处理,避免出现冲突或异常。
在 VAST 服务器将更改写入 V-Tree 的过程中,系统会创建新的元数据对象,并将事务令牌附加在其中。其他 VAST 服务器在访问这些元数据时,会检查对应的事务令牌状态,若事务已提交,就会读取最新数据并据此进行操作。
如果某个 VAST 服务器(发起请求的服务器)试图更新一个仍处于进行中事务的数据,它会先向“拥有该事务的服务器”发送轮询请求,以确认该服务器是否仍在运行,并在对方完成事务前暂时挂起自身操作。
但如果发起请求的服务器发现某一数据属于某个已经无响应的服务器(即事务失联),那么它将使用该数据的上一版本元数据来保持命名空间的一致性。同时,它也可以主动取消该事务并移除相关更新内容,防止死锁或数据不一致。这一机制确保了在高并发和服务器故障情况下,系统仍能保持强一致性和高可用性。
Bottom-Up Updates
设计高性能的事务型命名空间的关键之一,是在每个事务过程中尽可能减少因失败而导致命名空间不一致的风险,也就是说要尽量减少事务中可能出问题的步骤。VAST DataStore 采用了一种自下而上的更新方式,从 V-Tree 的底部节点开始向上进行更新,从而有效降低了事务中断所带来的影响。当客户端要覆盖一个已有文件的数据时,系统会执行以下步骤(这里为简化版本):
- 数据首先写入镜像的存储级内存(SCM)SSD 上的空闲区域,通过间接寻址方式实现;
- 随后创建元数据对象及相关属性,如 BlockID、生命周期、校验和等;
- 文件的元数据结构被更新,链接到上述新建的元数据对象;
- 只有当上述操作全部完成后,系统才向客户端发送写入完成的确认应答。
如果某次写入操作在完成第 4 步之前失败,系统会强制客户端进行重试。而在这次失败过程中遗留的旧数据或“断开的元数据”,将由系统后台的“清理(scrubbing)进程”自动处理,不影响文件的最终一致性。
相较而言,如果系统采用自顶向下的更新策略(比如先修改文件描述符以增加一个新区段,再写入区段数据和对应的块元数据),那么一旦事务中途失败,就会产生“指针指向空地址”的元数据错误,从而导致数据损坏。为了避免这种问题,系统就必须将整个操作封装为一个复杂的事务,并且在整个过程中锁定文件对象。
而 VAST 自下而上的设计,只在最终将新元数据链接到文件结构时才需要加锁,这意味着原本可能需要 20 次操作的事务,在这里只需在关键的 3 次写入操作上加锁即可。更短的锁定时间大大减少了资源争用,从而提升了系统的整体性能。
Element Locking
虽然元数据存储中的每一次读取操作都是无锁(lockless)的,但 VAST 集群内部在执行写操作时会使用写锁机制,以确保在多个并发写入场景下命名空间的一致性。这里使用的 Element Locks(元素锁) 与 Transaction Tokens(事务令牌) 不同:事务令牌主要用于在服务器发生故障时保障一致性,而元素锁则用于保障多个写入者同时操作同一数据范围时的写入一致性。
和事务令牌一样,元数据锁中也会签署上保留该锁的 VAST 服务器 ID。当某个 VAST 服务器发现某个元数据对象被加锁时,它会主动联系持有该锁的服务器,并同时执行机制以避免出现“僵尸锁”(即锁已失效但仍存在)的情况。整个过程无需依赖集中式的锁管理器,因此不会引入性能瓶颈。如果持有锁的服务器无响应,请求方服务器还会请求第三方的非关联服务器对该持有锁的服务器进行额外轮询,以防止误判,避免错误地将某台正常的服务器从集群中剔除。
为了保证写操作的高性能,VAST 集群会在元素所在的机箱(Enclosure)的 DRAM 中保存该元素锁的只读副本。VAST 服务器通过一次原子的 RDMA 操作直接访问机箱中 Fabric Module 的内存,即可高效地校验和更新锁的状态。这种设计极大地提升了锁状态检查与更新的效率。
以上锁机制主要适用于底层存储层面,而 VAST 集群在更高层面还提供了按字节粒度的文件系统锁定能力,这一内容将在后文“VAST Datastore: Protocols”章节中进行详细说明。
The Physical Chunk Management Layer
VAST DataStore 的物理层,也称为“块管理层”,在功能上类似于传统架构中的 SAN 存储阵列或逻辑卷管理器(LVM),主要用于在设备发生故障时保护数据,并负责底层存储设备的管理。
虽然这个物理层的职责类似于 RAID,即将写入的数据持久化并维护其完整性,但它采用的方法已经远远超越了传统 RAID 时代。例如,VAST 使用的是本地可解码的纠删码(Locally Decodable Erasure Codes),在容错效率与恢复速度方面都优于传统方案。更重要的是,VAST DataStore 使用统一的元数据结构来同时管理“命名空间”(即文件、对象、表等元素)和底层数据块(data chunks),这使得系统在进行数据布局时能做出更智能的决策。
传统的存储系统和文件系统之所以要极力减少随机 I/O,是因为机械硬盘的 IOPS 能力非常有限,因此只能依赖控制器 DRAM 中缓存的元数据来提升性能。但这种做法带来了两个问题:一是缓存一致性管理变得复杂,二是由于 DRAM 容量有限,文件系统设计者不得不简化元数据结构,具体表现为:
- 必须采用固定大小的空间分配块来写入、压缩和保护数据,这会在小文件与大文件之间产生权衡,影响压缩和数据利用效率;
- 必须引入如 RAID 集、卷(volume)和文件系统等中间抽象层来控制扩展性,但这也导致了命名空间的碎片化;
- 进行文件级的数据复制或纠删码处理,而不是面向整个系统的全局处理,这使得小文件管理与数据压缩更加复杂。
VAST DataStore 是专为 DASE 架构设计的,而在 DASE 集群中完全没有使用机械硬盘,因此也就不再需要像传统存储那样刻意优化顺序 I/O。
相反,VAST DataStore 的优化方向是面向低成本的超大规模闪存(hyperscale flash),重点在于最大化存储效率、最小化写放大效应。这是因为在传统系统中,频繁的数据重写和碎片整理会导致闪存“写放大”,从而快速消耗其写入寿命。而 VAST 的架构设计则是从根本上减少这种问题,以延长闪存设备的使用寿命,同时保障系统的高性能和低成本扩展能力。
VAST DataStore 在继承过去五十年存储技术精华的基础上,引入了多个创新性流程和数据结构,构建了一套面向未来的高效数据存储体系。其核心设计原则包括:
-
SCM 写缓冲机制:所有进入系统的数据,首先由接收的 CNode 写入两块存储级内存(SCM)的写缓冲区。只有当数据安全地写入这两块 SCM 后,系统才向客户端返回写入成功的确认,确保数据持久性。
-
异步迁移机制:写入 SCM 后,数据会异步迁移到超大规模闪存(hyperscale flash)中。这种异步设计不仅提高了系统响应效率,还为后续的数据压缩、去重等操作预留了处理时间,从而提升整体存储效率。
-
闪存管理优化:为延长闪存寿命,VAST 采用了多种写入优化手段。例如通过“Foresight”机制预测未来的数据访问模式,在垃圾回收时减少数据移动量;同时写入和删除操作以最小损耗的方式分批进行,从根本上减少写放大现象。
-
空闲空间写入布局(Write-in-free-space):VAST DataStore 始终将新数据写入到超大容量 SSD 上的空闲区域,并以完整的纠删码条带(erasure code stripes)为单位进行组织,从而优化写入效率和恢复能力。
-
按字节粒度管理(Byte Granularity):VAST 完全抛弃了传统存储中“固定大小分配块”的概念。系统支持任意大小的写入(从几字节到 1MB),物理块管理层根据写入实际大小管理 SCM 中的写缓冲块,而迁移到闪存中的“压缩后数据块”平均大小为 32KB(详见 Adaptive Chunking)。这两类数据块的指针都精确到字节级别(SSD、LBA、偏移、长度),无需填充对齐到固定块或 LBA 边界,极大提升了空间利用率。
-
突破性的相似性数据压缩技术:VAST 在数据从 SCM 迁移到闪存过程中,结合多种技术进行数据去重,数据压缩效率超过任何现有存储方案,尤其适用于重复数据密集的工作负载。
-
高效纠删码保护:VAST 使用本地可解码纠删码(Locally Decodable Codes),即使出现多达四块 SSD 同时故障,也能确保数据安全,而开销仅为 2.7%,远低于传统 RAID 系统。
总体而言,VAST 的物理层通过对数据进行变长切块、压缩、纠删码保护等操作,将复杂的存储任务抽象为高效、可靠的底层流程。在进一步深入这些机制之前,接下来我们将简要回顾一下数据在 VAST DataStore 中的完整流动路径。
Data Flows in the VAST DataStore
在深入了解 VAST DataStore 如何贯彻上述各项设计原则之前,我们先快速了解一下它是如何处理最基本的读写操作的。
Read
当某个 CNode 接收到读请求时,它会先通过集群中的一致性哈希表,定位到对应数据元素的元数据 V-Tree 根节点。随后,CNode 会沿着存储在 SCM 中的 V-Tree 指针向下查找,直到找到指向目标内容的数据块指针。
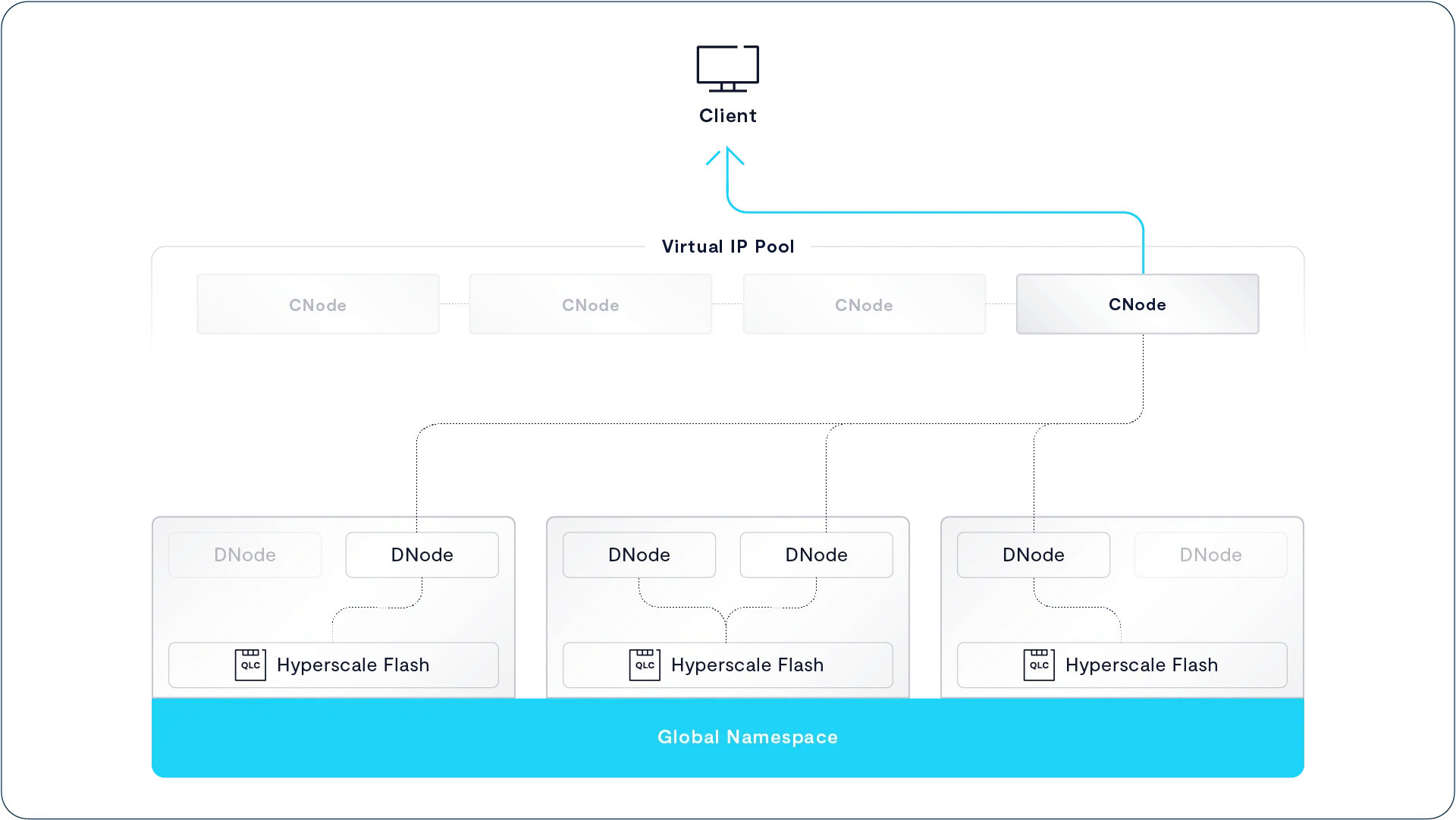
接着,该 CNode 会直接从超大规模闪存(hyperscale SSD)中读取这些内容块,将所需的数据组装完整后返回给客户端。
Write to SCM
当客户端向 VAST DataStore 中的某个数据元素写入数据时,接收该写请求的 CNode 会将数据写入到两块 SCM SSD 的写缓冲区中。如果启用了“静态加密”(encryption at rest),CNode 会在写入前对数据进行加密。
数据通常以与写入 I/O 大小相同的块(chunk)写入缓冲区,对于较大的写入操作,系统会将其拆分为多个数据块分别处理。
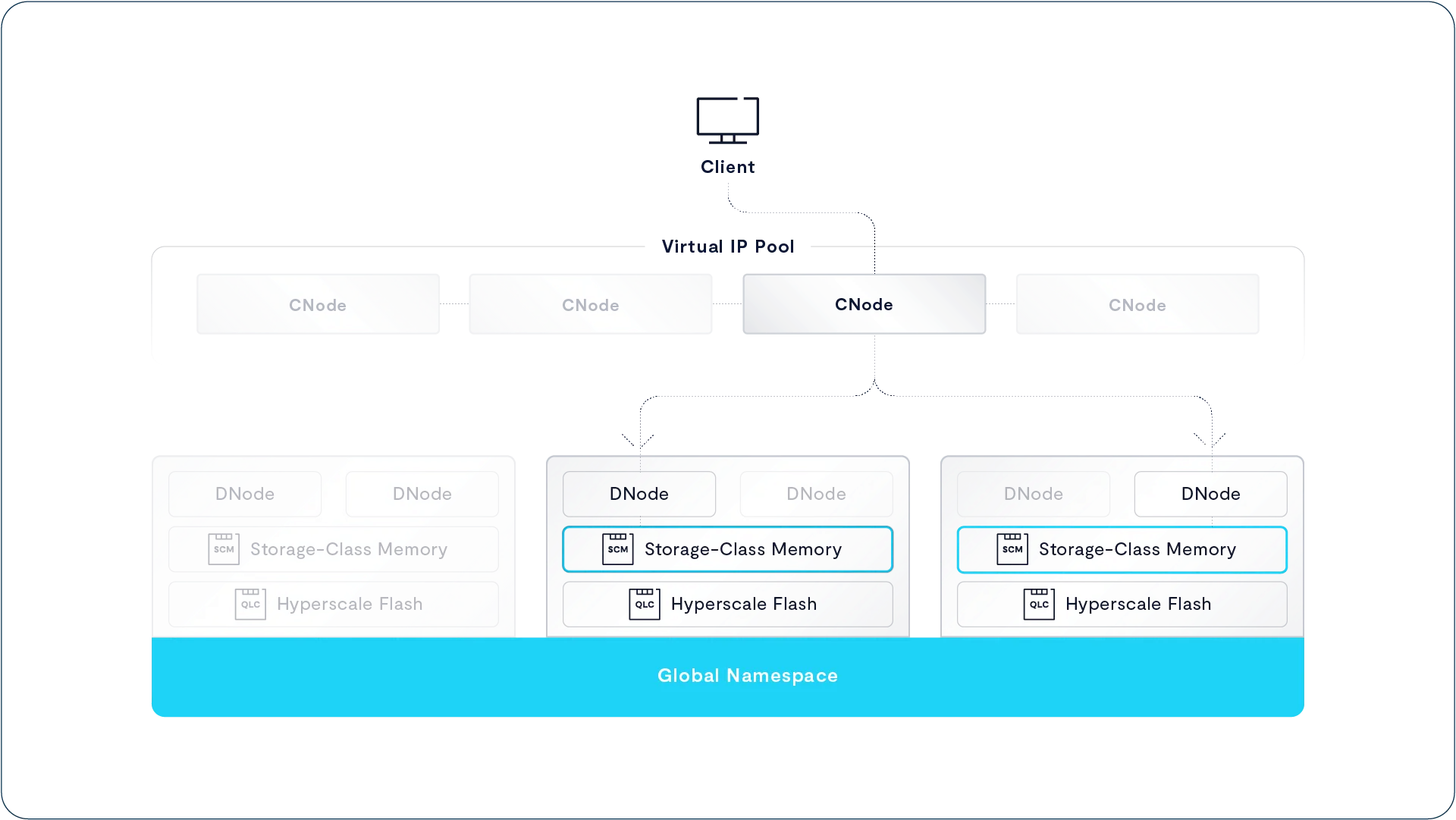
当数据成功写入两块 SSD 后,CNode 随即更新对应的元数据信息,并将这些元数据同样写入两块 SCM SSD 进行镜像存储。随后,CNode 向客户端发送写入成功的确认。
为了增强可靠性,系统尽量增加同一数据块或元数据块副本之间的物理距离。如果集群中包含多个 DBox,系统会将两个副本写入不同 DBox 中的 SCM SSD;而如果只有一个 DBox,系统则会选择连接至不同 DNode 的 SCM SSD,以降低单点故障风险。
Migrate to Flash
当集群中写缓冲区(SCM)中的数据量达到“高水位线”时,系统会启动数据迁移流程,将数据从 SCM 异步转移到超大规模闪存(hyperscale flash)。这一迁移过程是并行分布式执行的,由多个 CNode 协同完成。
每个参与迁移的 CNode 会从写缓冲区中读取数据,并对其进行压缩处理,将数据切分为平均大小在 16 到 64KB 之间的变长数据块。随后,这些经过压缩的数据块会被写入超大规模 SSD,并以超宽条带的本地可解码纠删码(Locally Decodable Erasure Code)方式存储,从而确保数据冗余与容错能力。
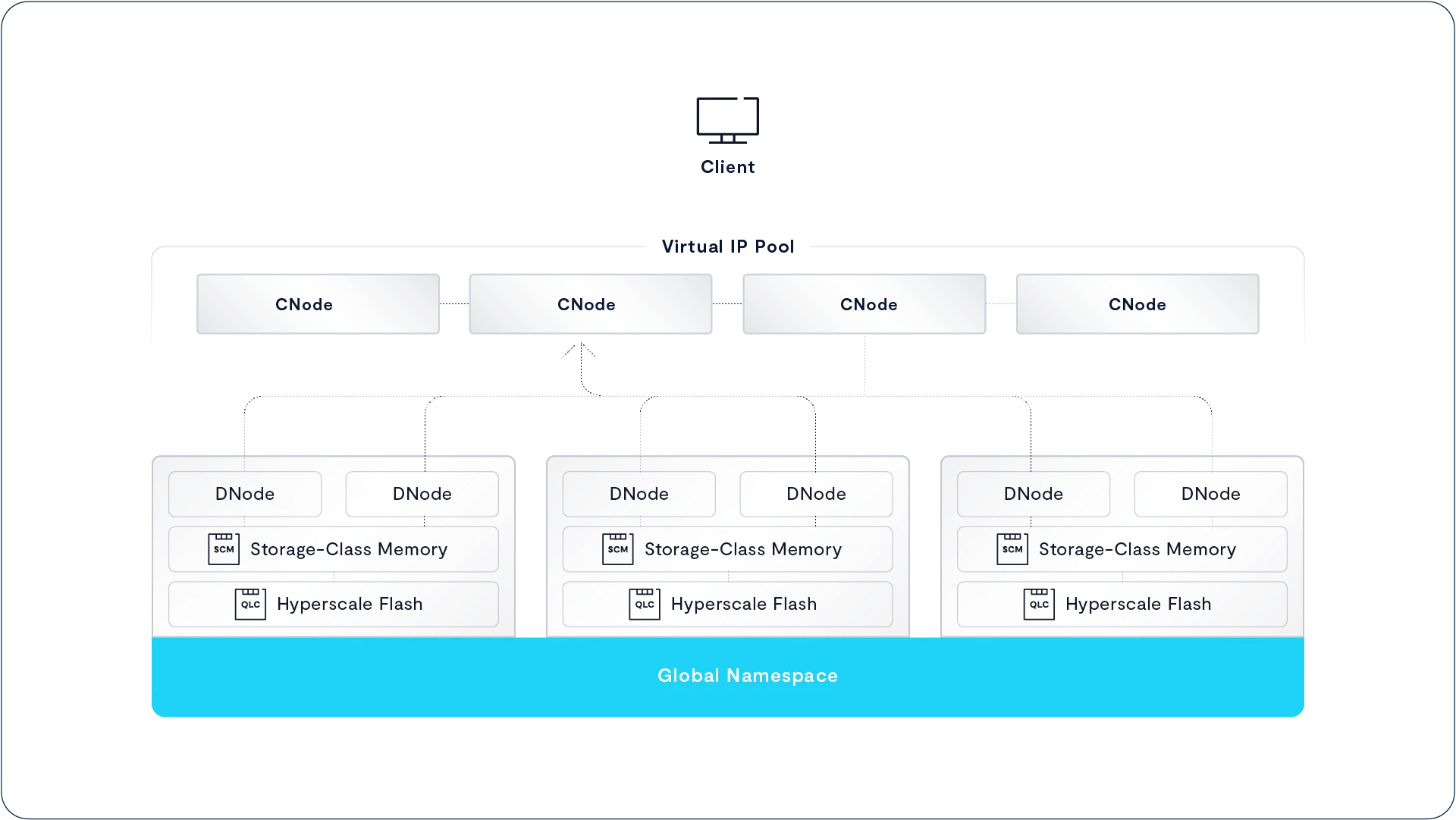
这种异步迁移机制不仅能实现“在线数据压缩”,而且能腾出时间进行更高效的数据去重与优化。由于迁移过程发生在客户端写入已经确认之后,压缩与迁移时间不会影响写入延迟。只要各个 CNode 处理写缓冲区的速度超过新数据的写入速度,那么单个数据块的处理耗时就不会影响整体性能。
当一组纠删码条带成功写入超大规模 SSD 后,CNode 会更新系统元数据,将数据指针指向新条带中的具体位置,并将之前使用的写缓冲区标记为“已释放”,以供后续写入新数据。
Write in Free Space Indirection
传统存储系统通常会将逻辑地址(例如某个视频文件 Little_Shop_of_Horrors.MP4 的第 100 万到第 400 万个字节)与其在物理存储设备上的位置建立静态映射关系。因此,当应用程序要修改该位置的数据时,系统会直接在原位置覆盖旧数据。在早期基于机械硬盘的存储架构中,这种静态映射有利于保持顺序数据在物理上彼此相邻,从而减少磁头移动,提高顺序读写性能。
但 DASE 架构下的系统不再使用机械硬盘,而是依赖低成本的超大规模闪存 SSD 提供存储容量。因此,在 VAST 集群中再去优化“顺序 I/O”的布局已毫无意义,系统的优化重点转向了闪存容量的利用效率与写入耐久性。
VAST DataStore 采用一种 “空闲空间写入”(write-in-free-space) 的数据布局策略,所有写入都通过“间接寻址”实现:新数据会从 SCM 写缓冲区迁移至超大规模闪存中,以完整的纠删码条带形式写入空闲空间。当某块数据被“逻辑覆盖”时,系统不会直接覆写原有数据块,而是仅仅更新对应元素(如文件、对象、表)的元数据指针,将其指向新的数据位置。

这种写入方式具有多项优势:
- 避免了传统“原地覆盖”操作中繁琐的“读-改-写”开销,显著提升系统性能;
- 天然支持指针机制,可用于实现低开销的快照、克隆、数据去重、数据复制等高级功能;
- 系统可以根据特定模式对 SSD 进行写入与删除操作,从而有效降低写放大,延长闪存寿命。
Challenges with Commodity Flash
廉价的通用型超大规模闪存(hyperscale-grade SSD)是 VAST DataStore 能够实现“归档级成本效益”的关键因素之一。但对于传统存储系统而言,在使用这类新型闪存技术时仍面临一些挑战:
-
写入性能:随着闪存制造商不断提高单位存储密度,每个存储单元内存储的比特数也越来越多,例如 QLC(每单元4比特)或 PLC(每单元5比特)。这使得 SSD 在写入数据时需要更精确地调整电压,从而导致写入时间变长,性能下降。
-
写入耐久性:写入寿命是制约通用型闪存应用的最大难题。某些超大规模闪存盘只能承受几百次重写,之后便会因磨损而失效。
针对这些问题,VAST DataStore 采用了SCM SSD 作为写缓冲区的策略。由于 VAST 系统在数据安全写入 SCM 之后就立即向客户端确认写入成功,因此即使后端 hyperscale SSD 写入延迟较高,也不会影响整体系统性能。此外,这套写缓冲机制还能帮助 VAST 在整个集群范围内有效分摊和管理闪存的写入寿命负担,延长设备使用周期。
Endurance Is Write Dependent
SSD 厂商在标注产品耐久性时,通常采用 DWPD(每天整盘写入次数,按5年寿命计算)或 TBW(可写入的总数据量,以TB计)这两个指标,这些指标是基于 JEDEC 标准负载模型评估的,其中 77% 的写入为 4KB 或更小的数据块。这种评估方式有其合理性,因为很多传统存储系统都是围绕 4KB 磁盘块设计的,而且用户在衡量闪存性能时也普遍使用 IOPS(每秒输入输出操作次数)这一指标,IOPS 的典型单位正是 4KB。
与此不同,VAST DataStore 是专门为最低成本的 hyperscale 闪存设计的。这种闪存与价格更高的企业级 SSD 不同:它们没有内置 DRAM 缓冲区,SSD 控制器无法像企业级 SSD 那样先在 DRAM 中积累数据再批量写入 NAND 闪存。这一点非常关键,因为对闪存进行小块写入(小于 128KB)会比等量的大块写入更快地消耗 SSD 的写入寿命。也就是说,哪怕写入的数据总量相同,频繁的小写入也会显著降低闪存的可用周期。
如下图所示,Intel P4326 这款 QLC SSD 的耐久性在不同写入方式下表现差异巨大:
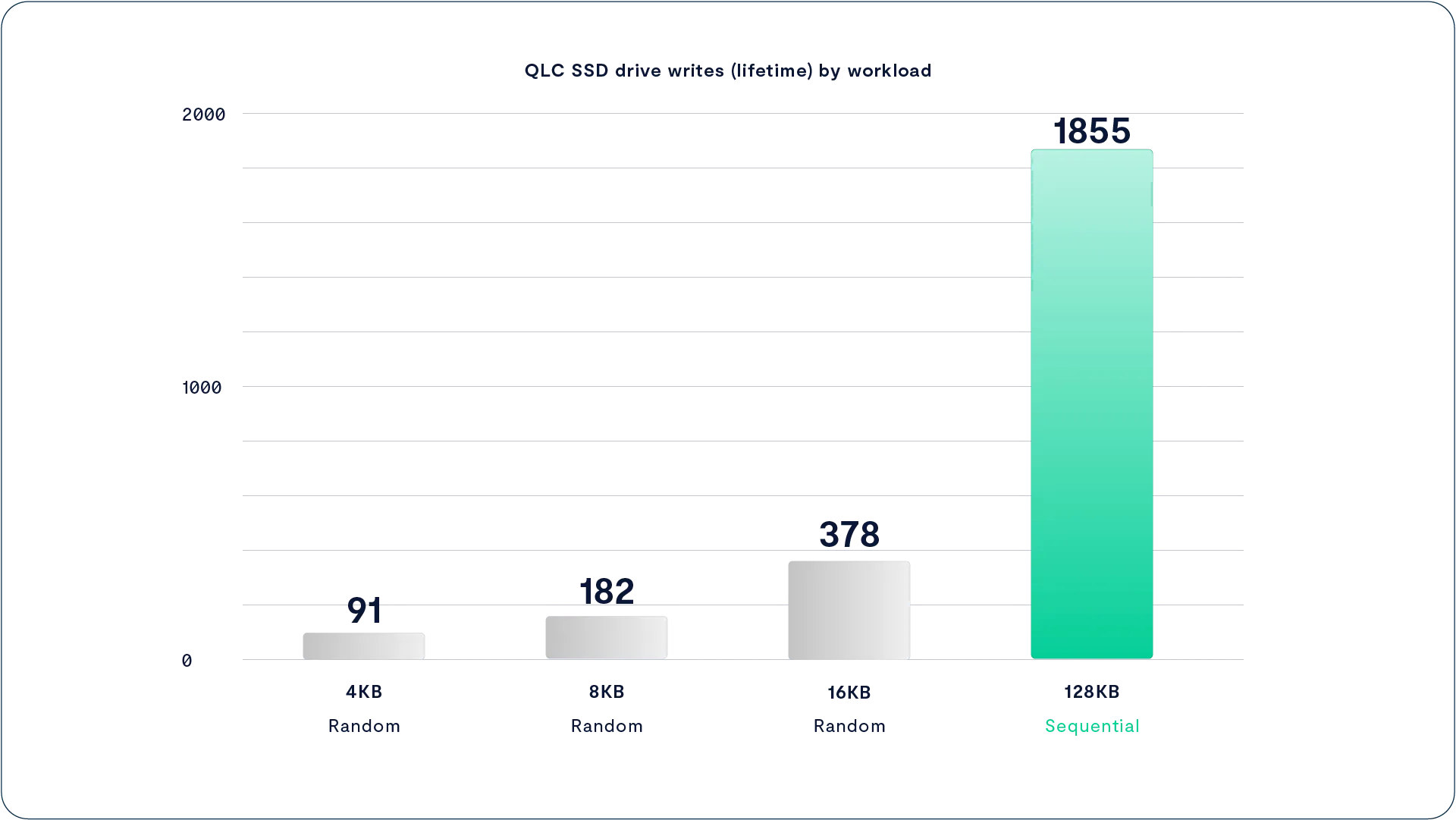
当以大块、顺序条带方式写入时,其耐久性可以达到以4KB 随机写入方式写入时的 20 倍,而后者正是许多传统企业存储系统中常见的写入模式。
之所以 hyperscale SSD 在大块写入时表现出更高的耐久性,是因为这种写入方式更符合闪存内部的物理结构。闪存是通过在存储单元中存储电荷(即一定数量的电子)来记录数据的。
控制芯片通过测量这些电荷形成的电压,来判断该单元的具体取值。对于 SLC(单层单元)闪存来说,这一判断非常简单:单元中有电荷就是 0,没有就是 1。而对于 QLC(四层单元)闪存来说,控制芯片需要在 16 个不同的电压等级之间做出区分,才能表示每个单元的 4 比特数据。
这意味着如果对 QLC 闪存进行小而随机的写入,不仅会增加误差率,还会造成内部频繁的擦写操作,大幅加剧磨损;而大块顺序写入则更容易对齐闪存结构,提高写入效率,同时显著延长设备使用寿命。
闪存芯片内部的存储单元组织结构非常复杂,但在实际管理中,主要需要关注其中两个关键层级:
-
页(Page):这是闪存中最小的可写单位。一旦某页被写入,就不能修改其中的内容,除非先对整页进行擦除。当前 hyperscale SSD 的页大小通常在 64KB 到 256KB 之间。
-
擦除块(Erase Block):一个擦除块由多个页组成(通常为 256 到 64K 个页),是闪存芯片中最小的可擦除单位。如今高密度闪存的擦除块通常有数兆字节之大。
当 SSD 控制器接收到新的写入数据时,会将数据写入一个空页中,并更新其内部的日志结构元数据。每次写入都会消耗该页所有存储单元的一次“编程/擦除(P/E)周期”。例如,如果你只写入 4KB 数据,但目标页大小为 128KB,那么整个页的寿命都会被消耗一次,造成严重的耐久性浪费。
当 SSD 可用空间不足时,控制器就需要进行垃圾回收(Garbage Collection)。它会将多个擦除块中仍然有效的数据重新整理(压实)到新的页中,从而可以对原擦除块执行擦除操作,释放空间以供新数据使用。
问题在于,擦除操作需要施加非常高的电压,这虽然对芯片内部是正常的设计,但会对存储单元内部的绝缘层造成微观损伤(即“量子动态磨损”)。随着擦除次数增加,这种磨损会导致电子逐渐泄漏,最终导致存储单元无法稳定保持电荷,也就无法可靠存储数据。
VAST Datastore Data Structures
Optimized for Hyperscale Flash
VAST DataStore 的设计核心之一是最大限度地减少写放大效应,也就是尽量减少同一份数据被重复搬移的次数。这种数据搬移通常发生在垃圾回收过程中,无论是在 VAST 自身的“空闲空间写入”机制中,还是在 SSD 控制器内部,都可能导致写放大。
为此,VAST 采取的第一步就是构建一个集群范围内的闪存转换层(Flash Translation Layer, FTL)。VAST DataStore 对整个集群中的 hyperscale SSD 进行统一管理,方式类似于 SSD 控制器对其内部闪存芯片的管理。
在这两种场景中,软件都借助了对底层硬件能力与限制的深入了解,从而以更智能、更高效的方式进行资源调度与写入规划。这种“全局级别”的闪存管理策略,有助于降低数据重复写入、减少闪存磨损,并显著延长设备寿命。
With Large Data Stripes, Drives Never Need to Garbage Collect
传统的基于间接寻址(indirection-based)文件系统,在整个数据管理流程中通常使用固定大小的逻辑块(如 4KB 或 32KB)。这种设计简化了存储系统的处理逻辑,特别是在构建文件系统元数据时,因为所有指针都只需要指向一致大小的数据块即可,大大降低了复杂性。
但这种方法也带来一个显著的问题:在小块与大块之间不得不进行权衡。小块有利于实现低延迟、细粒度的重复数据删除(Deduplication),但压缩效率低、闪存磨损高;大块则更易压缩、写放大更低,但牺牲了灵活性和精细控制能力。这让传统架构在设计时不得不做出取舍。
VAST Element Store 采用了完全不同的策略:不做妥协,而是针对数据在不同阶段的特点进行分层优化管理:
- 写入时:数据会以写入请求的实际大小写入 SCM 写缓冲区,从而最大限度减少延迟;
- 压缩时:数据会被自适应地分块,形成平均大小在 16KB 到 64KB 之间的变长数据块,并进行压缩或去重处理;
- 写入闪存时:这些压缩后的数据块会被紧凑地封装进纠删码子条带(substripe)中,每个子条带大小都是 SSD 页大小的整数倍,确保 SSD 控制器能高效写入整页数据;
- 容错时:每条纠删码条带由多个子条带组成,总大小往往远大于 SSD 的擦除块(Erase Block)大小,从而在实现高可靠性的同时,进一步减少写放大。
VAST DataStore 在写入数据到 SSD 时,采用的是 1MB 大小的 I/O 单元,这远远超过了底层闪存芯片每页通常 64KB–128KB 的大小。这种写入策略使得 SSD 控制器可以在内部将写入操作并行分发到多个闪存芯片上,提高写入效率。同时,它还能确保每个闪存页都被完整填满,避免因部分写入而引发的写放大问题。
在更高层面,Element Store 会将这些 1MB 的写入条带进一步组织成每个 SSD 上 1GB 大小的“深条带”(strip)。就像将 1MB 对齐写入可完整覆盖多个闪存页一样,1GB 的数据条带也可以与 SSD 内部多个擦除块(Erase Blocks)对齐,提高擦除效率。
当 VAST DataStore 执行垃圾回收时,会直接在每块 SSD 上整体擦除整条 1GB 的纠删码条带。这意味着 SSD 控制器可以一次性清除多个擦除块中的所有内容,不需要将残留的有效数据搬移到别处,从而避免了 SSD 内部再进行二次垃圾回收,显著降低闪存磨损。
值得注意的是,1GB 的条带深度和 1MB 的子条带大小并不是 VAST 架构中固定不变的参数,而是通过大量实验测试得出的结果,目的是在当前一代高容量 SSD 上实现最小化磨损。随着新的闪存类型(如 PLC 闪存)的进入以及新 SSD 的引入,VAST Cluster 的写入布局也可以灵活调整,以适应未来闪存对更大写入单元和擦除粒度的需求,从而继续优化设备寿命与性能。
VAST 能够实现上述智能数据布局,离不开其底层架构中几个关键组件的支撑:
首先,系统构建了一个由 SCM(存储级内存)组成的大规模分布式写缓冲区,它为系统提供了充足的时间,能够聚合足够多的数据块来形成完整的纠删码写入条带,例如规模为 146+4(即 146 个数据块 + 4 个冗余块)的条带。在这个过程中,应用程序可以迅速收到写入确认,无需等待数据完整地写入到后端的 hyperscale 闪存,从而实现低延迟响应。
其次,系统基于 NVMe over Fabrics(NVMe-oF)协议和 NVMe SSD 构建了一个“共享一切”(shared-everything)的集群架构,这使得多个 CNode 可以协调一致地将 1MB 写入条带准确地填充到 SSD 的擦除块中,实现高效写入、低损耗、最大限度减少写放大效应。
VAST Foresight
Retention-Aware Data Protection Stripes
写入空闲空间(write-in-free-space)这种数据布局方式的一个主要缺点是,随着系统运行,空闲空间会逐渐耗尽,最终必须执行垃圾回收(garbage collection),将已删除或被覆盖的数据与仍然有效的数据分离,并将有效数据重新搬移到其他位置。这个过程往往会产生写放大效应。为此,VAST 引入了 Foresight 机制,它通过根据数据的预期寿命将其写入不同的纠删码条带,从而有效减少垃圾回收带来的写放大。
在 Foresight 出现之前,传统存储系统通常是按照数据写入顺序将其依次写入设备的。如果某一组主机在进行《福尔摩斯大战德古拉》的最终渲染输出,而另一组主机则在写入另一个项目中的数千个临时文件,这两类数据就会被交错写入存储系统。
如果该系统采用的是类似日志结构或“写入空闲空间”的布局,那么在临时文件被删除后,系统仍需执行垃圾回收,把这些与渲染数据混杂在一起的“无效数据”清理出来。结果就是:即使渲染数据在逻辑上从未移动过,也会被反复搬移,仅仅是因为它混在了易失数据中。这种重复搬移会持续几年时间,每次都会消耗闪存寿命,浪费宝贵的写入资源。
而 VAST 的 Foresight 能够识别哪些数据可能短命(如缓存、临时文件),哪些更可能长期存在(如最终渲染输出),并将它们分配到不同的写入区域,极大减少后期清理和搬移的必要性,从而提升系统效率并延长闪存使用寿命。
与传统存储系统不同,Foresight 不再按照数据写入的时间顺序存储数据,也不会为了优化机械硬盘的顺序读取而将逻辑上相邻的数据物理上靠近。而是根据数据的“预期寿命”(life expectancy),将其组织进不同的纠删码条带中。VAST DataStore 物理层中描述每个数据块的元数据,都包含一个“寿命预估”字段。
当系统构建纠删码条带时,会将寿命相近的数据块组合在一起。例如,临时文件和最终渲染文件将被写入不同的条带。这样,当临时文件被删除后,其所在条带大部分都是无效数据,几乎无需移动大量有效数据就能完成垃圾回收。
VAST DataStore 只有在系统剩余空间低于“低水位线”时才会触发垃圾回收,并且优先回收那些可释放空间最多的条带。配合 Foresight 的数据分布策略,这种回收机制能够以最少的数据搬移释放出最多的可用空间。
被参与回收的数据块,其元数据中的“寿命预估”值会被自动提高。随着时间推移,那些真正长期存在的数据会逐渐被系统聚集到专门的 “永久存活条带”(immortal stripes)中。这种设计彻底避免了传统系统中反复搬移不变数据所造成的资源浪费,提高了闪存的使用效率与整体系统的耐用性。
Endurance Is Amortized
Wear-Leveling Across Many-Petabyte Storage
VAST DataStore 还通过一种全局擦除块池化管理机制进一步延长闪存寿命。它将整个集群中 PB 级别的闪存资源视为一个统一的“擦除块池”,集群中的任意 VAST Server 都可以对这部分资源进行统一调度与管理。基于这一架构,VAST 集群能够在整个闪存池范围内进行跨节点的写入均衡(wear-leveling),即使面对高频率数据变动的工作负载,也能将其写入压力摊薄到整个集群的 PB 级闪存资源中,从而显著减少局部磨损。
由于 VAST 采用的是横向扩展(scale-out)架构,系统所需关注的仅是各类应用在集群内的加权平均写入率。例如,一个持续以 4KB 单位更新数据的数据库,在一天之内也只会重写集群中极小一部分闪存资源,而不会造成整体负担。
VAST 集群的大规模特性还使其能以 150GB 级别的纠删码条带(stripe)进行垃圾回收,这种大规模条带设计不仅最小化了闪存磨损,同时也降低了数据保护的附加开销。与一些传统“写入空闲空间”机制不同的是,VAST Element Store 即便在系统容量已使用高达 90% 的情况下,依然能够保持完整性能不下降,确保在高利用率场景下依旧具备企业级的稳定性与响应能力。
A Breakthrough Approach to Data Reduction
数据压缩的发展历史主要集中在两种核心技术的演进:压缩(compression)和去重(deduplication)。这两种方法互为补充,都是通过计算能力来减少存储数据所需的空间。压缩技术较早出现,擅长在较小的数据范围内识别和压缩重复的比特模式;而去重则能在更大数据块和更广数据集范围内消除重复内容。
VAST DataStore 不仅结合了这两种传统技术,还引入了一种新型的数据优化方法,称为相似性去重(similarity reduction)。它能识别并优化那些与现有数据块相似但不完全相同的数据,从而进一步节省存储空间。
Beyond Deduplication and Compression
传统压缩技术通常作用于一个数据块或一个几 KB 到几 MB 的文件范围内。压缩器会识别出其中重复出现的小型数据模式,例如数据库字段中的空值填充(null padding)或频繁出现的词语。系统会用更短的符号替换这些重复模式,并创建一个“字典”,用于说明每个符号代表的真实数据内容。当系统读取数据时,会通过这个字典进行解压,把符号重新还原为对应的原始数据字符串。
许多文件类型,尤其是媒体类文件(如音视频),在文件格式本身中就内嵌了压缩机制。这些压缩方法通常针对特定媒体类型进行了专门优化,比如 H.264 或 MPEG 格式会以“与上一帧相比发生变化的像素”来保存帧数据,这种方式比通用存储系统的压缩算法更高效。因此,在某些非结构化数据场景下,存储系统的通用压缩算法可能无法显著提升压缩率。
相比之下,数据去重(deduplication)关注的是在整个存储命名空间中识别出大规模重复的数据块。与存储多份相同数据相比,去重系统会仅保留一个物理副本,其余重复内容则通过指针引用该副本。
大多数去重系统会将数据切分为大小在 4KB 到 1MB 之间的数据块,并对每个块进行哈希处理。系统会查找重复的哈希值,并将重复出现的第 2 到第 n 个相同块,仅存为指向第一个块的引用指针,从而显著节省存储空间。
由于去重存储系统是通过指针引用来管理数据的,因此在读取数据时,系统需要将这些被“去重”的数据重新还原(rehydrate)成连续的数据流。虽然逻辑上数据是顺序排列的,但实际上这些数据块在存储中可能分布在不同位置,这就会导致系统在读取过程中产生大量随机 I/O 操作,尤其是在进行顺序读取时也需要“跳着”读取数据块。
对于以机械硬盘为后端的去重系统来说,这种模式会大幅拖慢读取速度,因为硬盘需要频繁移动磁头(即“磁头震荡”),极大增加了延迟。而如果使用 SSD 作为后端,随机和顺序 I/O 的速度几乎一样,因此可以消除这类“还原开销”。
此外,去重系统所采用的数据块哈希机制对细微差异非常敏感,哪怕两个数据块只有 1 字节的不同,也可能导致去重系统不得不完整保存一个新的数据块。这意味着系统花费大量计算资源进行哈希计算,却未必带来显著的空间节省,反而得不偿失。
为了减少这种对数据“熵”(即不确定性、随机性)的敏感性,有些去重系统会尝试采用更小的去重块。虽然这有助于发现更多重复数据,但也带来了新的问题:小数据块会产生更多元数据,系统需要在内存中维护更大的哈希表。大多数去重系统将哈希表保存在 DRAM 中,这就意味着更小的块会消耗更多内存和 CPU 资源来进行管理,而且在成本和性能之间可能得不偿失。
Similarity Reduction to the Rescue
将超大规模闪存、十年系统寿命,以及突破性的纠删码效率相结合,为那些希望降低全闪存或混合(闪存 + 机械硬盘)基础架构成本的企业,提供了极具吸引力的经济方案。而 VAST 提出的全局数据压缩方式——基于相似性的压缩(similarity-based reduction),进一步重塑了闪存的成本结构。如今,企业可以打造出一套系统,其单位有效容量的采购成本甚至能媲美或优于传统全机械硬盘架构。
VAST 的目标很明确:将去重技术带来的全局数据优化优势,与按字节粒度进行模式匹配(以前仅见于本地文件或块级压缩中的特性)相结合,打造出兼具灵活性与高压缩率的新型存储体系。
在这种架构下,闪存系统可以对数据进行精细划分与相关性分析,最终落盘的数据块极小,从而将一切工作负载都转化为 IOPS 密集型操作。而在 VAST 提供的架构中,系统的 IOPS 几乎可以视作“无限”,因此即使处理这类密集的小数据读写,也能轻松应对,成为理想应用场景。
反观 HDD(机械硬盘)系统,在处理类似的小块、随机读写工作负载时,会造成严重的碎片化,且硬盘本身的 IOPS 能力远远无法满足如此高频的随机访问需求。
Similarity Reduction
当数据写入 VAST DataStore 时,系统首先将数据写入存储级内存(SCM)写缓冲区,并立即向客户端发送写入确认(ACK)。随后,VAST DataStore 会在将数据从 SCM 写缓冲区迁移到超大规模闪存池的过程中,执行数据压缩与去重等数据缩减操作。
由于写入操作在数据落入 SCM 后就已被确认,因此系统拥有充足的时间来进行更精细、更深度的数据压缩处理。只要系统清空写缓冲区的速度不慢于新数据的写入速度,那么压缩和迁移所耗费的时间不会影响系统整体性能或写入延迟。
自适应分块(Adaptive Chunking)是 VAST 系统中用于提升存储效率的重要机制。系统会使用滚动哈希函数将数据划分为变长的数据块,平均大小在 16KB 到 64KB 之间。随后,系统会对每个数据块应用多种哈希算法,其中包括强哈希算法,用于为每个数据块生成一个唯一标识符。
和传统的去重机制一样,当系统检测到有多个完全相同的数据块写入时,它只会保留一份数据副本,其余部分则通过元数据指针引用该副本,从而节省存储空间。
不同的是,VAST 系统还会对每个数据块使用一系列相似性哈希函数进行额外处理。传统的强哈希(如用于去重)追求抗碰撞性:哪怕输入数据只发生了微小变化,输出哈希值也会发生巨大变化,确保不同数据块不会产生相同的哈希值。而相似性哈希则属于 “弱哈希” ,其目标是:对内容接近的数据块,产生相同的哈希值。换句话说,如果两个数据块之间只需要翻转少量比特即可互相转化,那么相似性哈希就会将它们映射为相同的值。
从实际效果来看,如果只需少量比特翻转就能将块 A 变为块 B,这说明这两个块之间存在大量重复的字节序列。这也意味着它们可以使用相同的压缩字典将这些重复序列编码成更短的符号,实现高效压缩。
当一个新数据块生成了一个独特的相似性哈希值,说明该数据块与已有数据没有明显相似性,此时系统会使用 ZSTD 压缩算法对其进行压缩。ZSTD 是由 Facebook 开发的一种压缩算法,特别优化压缩性能。压缩后的数据会被加入到当前 CNode 正在构建的纠删码条带中。
而当一个新数据块生成的相似性哈希值与某个已有数据块一致,说明它们在内容上具有高度相似性。此时系统会回调原始参考数据块,并使用参考块的压缩字典对新数据块进行压缩。最终,系统将这个新数据块以“差异块(delta block)”的形式进行存储,而无需重复存储压缩字典,从而节省更多空间和资源。
A Single Reduction Realm
如前所述,传统的去重系统为了保证处理速度,必须将哈希表存储在 DRAM 中。但这种做法也带来了限制:能去重的数据量受到单个控制器内存容量的限制。即便是专为备份设计的大型设备,其可去重数据量也通常只有约 1PB。一旦数据集变大,必须跨多个设备分布时,每台设备就会变成一个独立的去重域(deduplication realm),结果是:相同的数据块如果写入了多个设备,就会被重复存储。
此外,有些系统只在卷(volume)、文件系统,或其他中间抽象层内进行去重,这会进一步增加去重域的数量,从而降低去重效果,也导致一些高频出现的数据块被存储了多个副本。
对于横向扩展(scale-out)架构的系统而言,去重面临的挑战更大:要在整个集群中维持一个统一的哈希表,就必须在节点之间频繁进行“东西向通信”,而这会带来巨大的网络负载,使去重变得不切实际。最终结果是:很多横向扩展系统要么干脆放弃去重,要么只能在每个节点上使用本地哈希表,相当于把每个节点变成一个独立的去重域,从而牺牲了全局优化的可能性。
而 VAST 系统则彻底改变了这一模式。它将哈希表及其他 DataStore 元数据存储在高可用(HA)的 DBox 中的 SCM SSD 上。由于这些 SCM 是在整个集群中共享的,所以 VAST 能够将整个集群视为一个统一的数据压缩与去重域,无论是传统去重还是相似性去重都可以全局执行。
更关键的是,每当有新的 DBox 加入集群,它就会带来额外的 SCM 存储资源,因此这个单一的去重域可以线性扩展到 EB(百亿 GB)级别,为大规模数据集提供一致且高效的数据缩减能力。
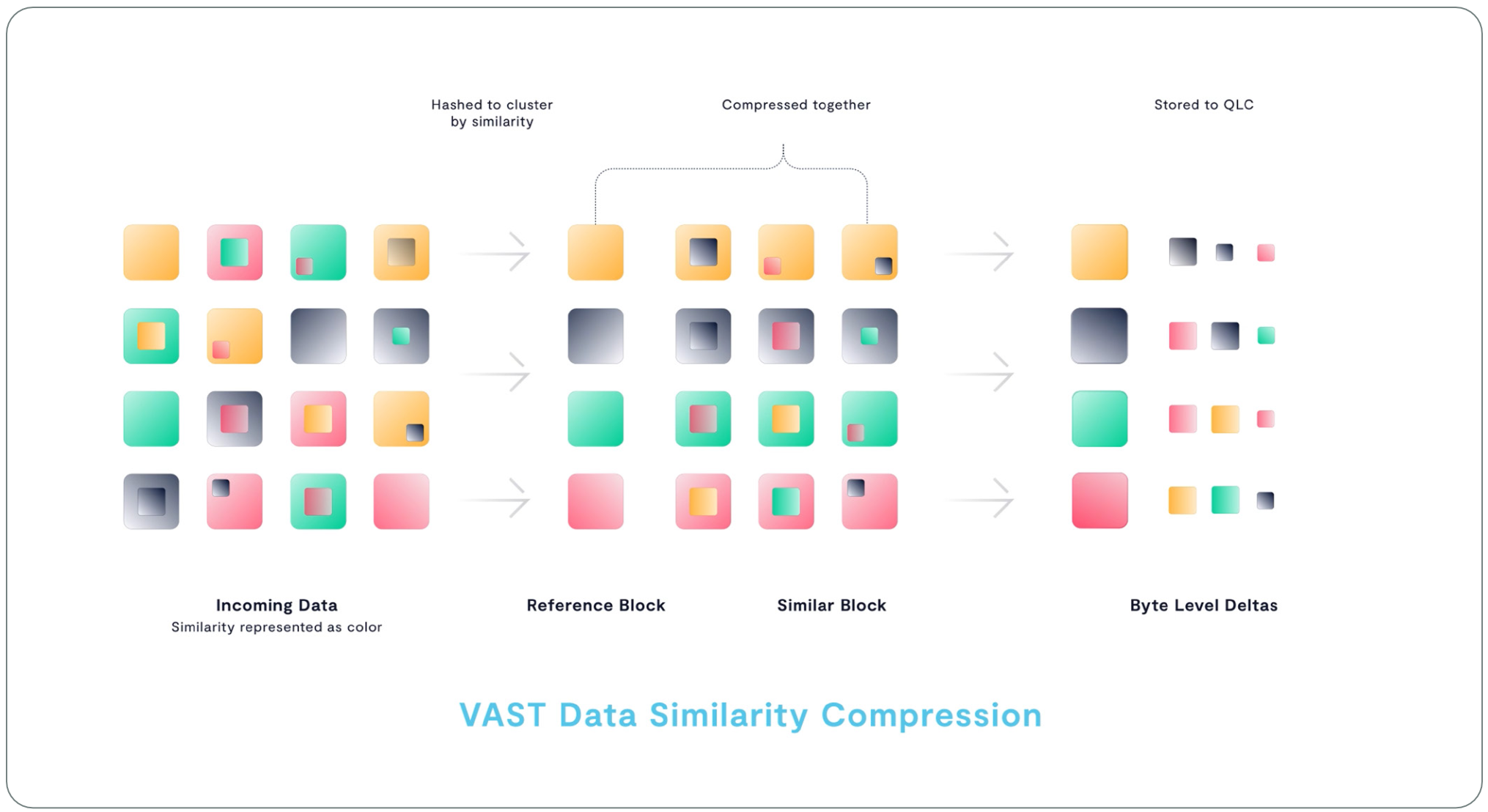
Similarity Reduction in Practice
基于相似性的压缩(similarity-based data reduction)在实际效果上确实依赖于具体数据的类型。对于加密数据来说,这种方法(以及其他所有压缩方式)几乎都无法带来任何压缩收益。但在许多其他应用场景中,这种技术往往能带来显著的存储节省。
当然,压缩收益是相对而言的——比如在备份数据场景中,VAST 集群的压缩效果可能比传统去重设备高出 2 倍,实现 15:1 的压缩比;而在一些非结构化数据环境中,传统文件存储系统几乎无法实现压缩,而 VAST 即使只达到 2:1 的压缩比,也是非常有价值的优化。
以下是 VAST 在实际客户测试中实现的相似性压缩效果示例:
- AI / 机器学习训练数据:3:1
- 企业级备份文件:最高 20:1
- 日志存储(包含索引和已压缩内容):4:1
- 多租户高性能计算(HPC)环境:2:1
- 已压缩的金融服务市场数据(如 GZIP):1.5:1
- 已压缩的视频数据:1.1:1
- 地震数据:3:1
- 影视特效与动画数据:3:1
- 天气数据:2.5:1
A Breakthrough Approach to Data Protection
保护用户数据是所有企业级存储系统的首要目标。然而,传统的数据保护方案,如数据复制、RAID 以及 Reed-Solomon 纠删码,往往需要在性能、可靠性、存储开销和系统复杂度之间做出艰难的取舍。为了解决这些问题,VAST DataStore 结合了存储级内存(SCM)和 NVMe-oF(NVMe over Fabrics)技术,并引入创新型纠删码,能够在保持高性能和高可靠性的同时,实现前所未有的低开销与低复杂度。
VAST 集群架构的一个核心设计理念是:将传统方法下高达 200% 的系统开销(比如三副本存储)降低至仅约 3%,同时使系统的容错能力比三副本和传统纠删码方案更强。最终,VAST 实现了一种全新的纠错编码体系,不仅提供了极高的容错性(如 数百万小时的平均无数据丢失时间),同时将存储开销控制在非常低的水平(通常低于 3%)。
Wide Stripes for Storage Efficiency
实现高效数据保护的关键在于使用更宽的纠删码条带(erasure code stripes)。举个例子:一个条带中包含 8 个数据块和 2 个校验块(即 8D+2P),其存储开销为 20%;而如果扩展为 14D+2P,开销就降到了 12.5%。条带越宽,校验块所占的比例越低,系统效率也就越高。
在传统的 共享无状态(shared-nothing) 架构中,一旦某个节点出现故障,该节点上的所有硬盘都会离线。因此,系统必须将整个节点视为故障单元,不仅要在硬盘之间进行条带化,还必须跨节点进行数据分布。这会限制条带的宽度,增加开销。
而 VAST 所采用的 DASE 架构 使用的是高可用的存储机箱(DBoxes),允许系统在整个集群中对所有 hyperscale SSD 进行条带化写入,因为任何一次硬件故障最多只会影响一块 SSD,无需担心整个节点离线。
由于 SSD 的数量通常远多于存储机箱的数量,这意味着 DASE 集群可以构建更宽的纠删码条带,最大可达 每条 150 个块。这比 shared-nothing 架构的冗余效率要高得多。例如:
- 在 VAST 的一组 JBOFs(Just a Bunch of Flash)中,系统可以构建一个 146+4 的 SSD 写入条带,在单个机箱内跨盘写入,实现冗余保护;
- 如果一个 shared-nothing 集群想要达到同样的条带宽度,它需要近 40 台存储服务器才能做到,代价极高。
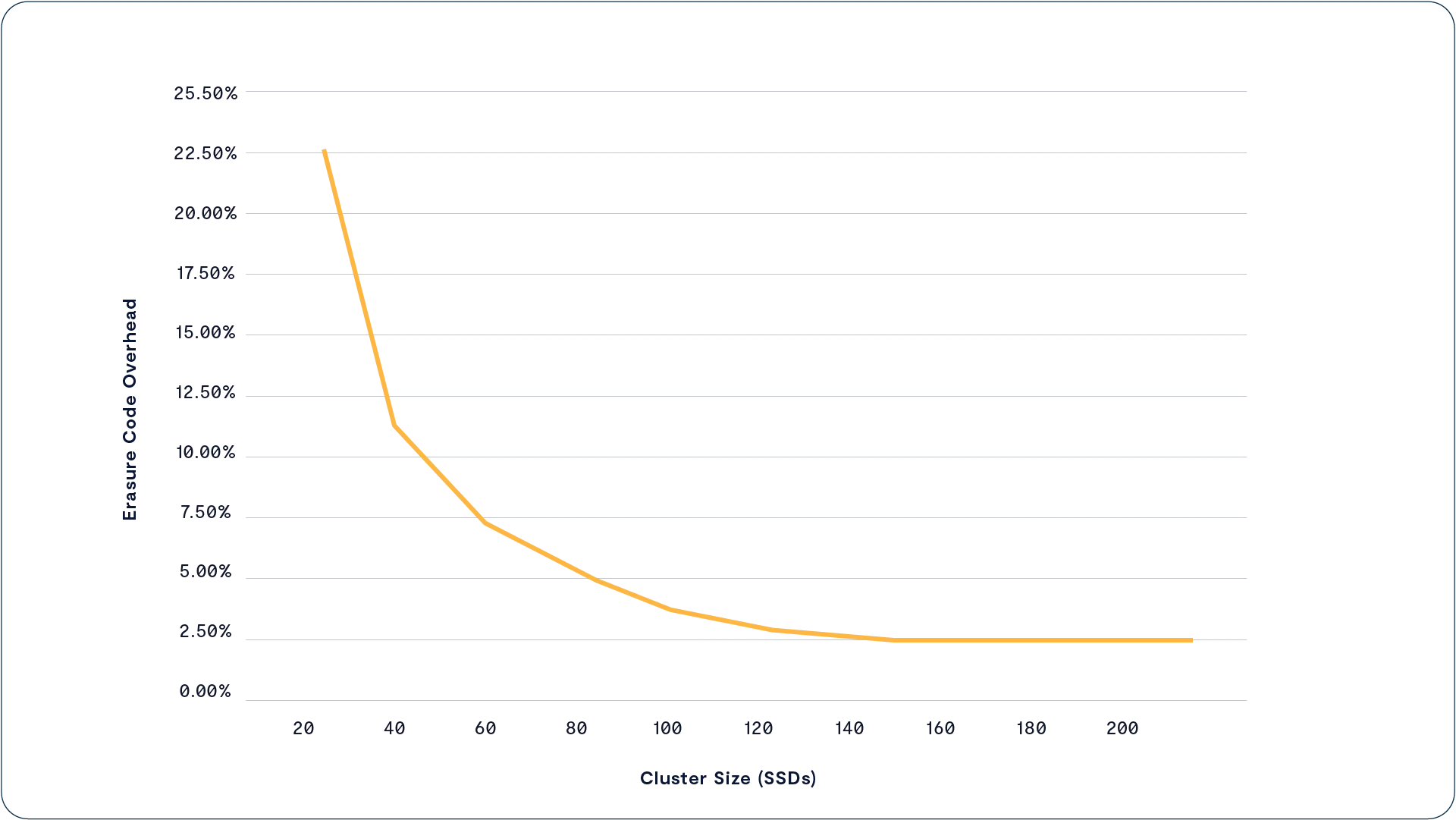
Quad Parity for Higher Resilience
宽条带写入(wide write stripes)是提升存储效率的关键手段,但与此同时,它也会带来一个问题:随着条带中设备数量的增加,多个设备同时故障的概率也会相应提高。尽管闪存 SSD 的可靠性远高于机械硬盘,但从统计角度来看,在一个 146+2 的条带中(共 148 块 SSD),发生两块 SSD 同时故障的概率,远高于在一个 10+2 条带中(共 12 块 SSD)出现同样故障的概率。
为了既能支持宽条带带来的高效率,又能满足 EB(Exabyte,百亿 GB)级别数据仓库所需的 “11 个 9”(99.999999999%)数据持久性保障,VAST 系统在所有纠删码条带中统一使用 4 个校验块(4 parity strips)。这意味着即使同时发生多达 4 块 SSD 故障,系统也能在不中断服务的情况下完成数据重建,保障用户的持续访问和数据完整性。
虽然通过增加校验块确实可以提升条带的容错能力,但这还不足以完全抵消更宽条带带来的更高故障风险。因此,VAST 在设计上还必须关注另一个关键点:最小化恢复时间(Time to Recovery,TTR)。
VAST Data Locally Decodable Codes
存储系统过去一直倾向于使用较窄的纠删码条带,这是因为它们普遍采用的是 RAID 或 Reed-Solomon(RS)类纠删码。这类编码要求系统在重建数据时,必须读取条带中所有存活的数据块以及一个或多个校验块,才能从硬盘故障中恢复出丢失的数据。
举个例子来说明这个问题:假设一个存储系统使用与 VAST 大型集群相同的条带布局,即每个纠删码条带由 146 个数据块 + 4 个校验块(146D+4P) 组成,并采用 Reed-Solomon 纠删码。当其中一块 SSD 故障时,系统需要读取其余所有 146 块数据 SSD 的内容,再加上一个校验块,才能重建丢失数据。这意味着,系统为了修复一块 SSD,实际上需要处理 相当于那块 SSD 容量的 146 倍的数据量。
为了避免这种规模的重建操作——它可能会持续几天甚至几周,并消耗系统大量性能资源——传统存储厂商会将每条纠删码条带的总块数控制在较小范围内(通常低于 16 到 24 个数据块加校验块)。通过缩小条带宽度,限制故障影响范围,从而减轻重建压力。
为了解决这一问题,VAST Data 设计了一类全新的纠删码,基于一种被称为 “本地可解码码(Locally Decodable Codes)” 的新算法思想。其核心优势在于:在发生故障时,系统不需要读取条带中所有存活的数据块,而是只需读取其中的一部分,即可完成数据重建。所需读取的数据比例,取决于该条带中配置的校验块数量。
比如在一个 146D+4P 的 VAST 条带中,系统只需读取 38 个数据块(即约 1/4) 就能恢复丢失内容,大大减少了 I/O 压力和恢复时间。这种机制让超宽条带既能保持高效率,又不会牺牲数据恢复能力。
How Locally Decodable Erasure Codes Work
VAST 的本地可解码纠删码(Locally Decodable Codes)通过一种更灵活的方式来计算每个校验块(protection strip):它们不是仅依赖于某一条数据条带中的固定数据块集合,而是跨越多个数据条带,从略有不同的数据块组合中计算得出。
这种设计使得校验块在重建过程中可以“代替”一大批数据块参与计算。具体来说,系统可以让其中 3 个校验块“代替”整个条带中 3/4 的数据块,这样在实际进行数据重建时,仅需读取剩下的 1/4 存活数据块就能完成恢复操作。
Storage-Class Memory Eliminates the Need for Nerd Knobs
许多传统存储系统会让管理员面对各种复杂的 RAID 保护级别和条带宽度选择,设置繁琐、易出错。而 VAST DataStore 则通过架构设计简化了这一点,它始终采用固定的 n+4 纠删码保护机制,无需管理员反复配置。实现这一简洁性的关键在于:VAST 系统中大容量的 SCM(存储级内存)写缓冲区将写入延迟与后端纠删码条带布局解耦。
换句话说,系统在数据写入到 SCM 后立即向应用程序确认写入成功,而实际的纠删码编码过程和数据迁移操作是异步完成的,这有效降低了写入延迟。
所有写入 SCM 的数据都会被镜像存储到两块 SCM SSD 上。SCM 不同于闪存:它没有 LBA(逻辑块地址)、页、块等层级结构,也不存在由这些结构带来的写入复杂性。更重要的是,SCM 拥有极高的写入耐久性,而且不受写入模式的影响,不像闪存那样容易因小块随机写入而加速磨损。这意味着,无论应用的 I/O 大小如何组合,SCM 写缓冲区都能始终保持高性能。应用写入的数据会立即写入多块 SCM SSD,一旦写入完成,就立即向应用确认,而数据迁移到后端闪存是在写入确认之后再异步进行的。
另一方面,VAST 系统在读取数据时也具备出色性能。这得益于两个方面的设计:首先,闪存天然支持高速随机访问;其次,VAST 采用了宽条带写入和校验去中心化(parity declustering),使所有写入都能在多个闪存设备之间并行展开。
需要强调的是,本地可解码纠删码并不要求每次读操作都读取完整条带。实际上,读取操作可以小至一个 SSD 中的数据块,也可以大到跨越多个条带。因此,条带的宽度和用户读取的文件、对象、目录或桶的大小之间,并不存在严格的一一对应关系,而是相对松散关联。
Intelligent, Data-Only Rebuilds
VAST DataStore 能够准确掌握每块 SSD 上哪些块存储着活跃数据,哪些是空闲的,哪些虽然被占用但实际上保存的是已删除的数据。当某块 SSD 发生故障时,系统只需要复制那些仍然活跃的数据块,而可以完全忽略已删除的数据和空闲空间。
Declustered Parity
VAST DataStore 并不会将 SSD 分组用于存放数据条(data strips)、奇偶校验条(parity strips)或备用盘(spares),而是将纠删码条带分布在系统中所有的 SSD 上。系统根据每块 SSD 的可用空间和磨损情况来决定每条数据应该写入哪些 SSD,而不是根据数据本身的位置。数据随后通过多个子条带(sub-stripes)分层写入每个 1GB 的主条带中,而这些子条带可以由不同的 VAST Server 同时写入。
由于 DASE 架构是“共享一切”(shared-everything)设计,数据恢复过程可以被分片(shard)并在整个集群的 VAST Server 上并行进行。VAST 采用解聚集(declustered)的数据保护策略,确保每块设备上都保存了来自不同条带的一部分数据和奇偶校验信息。这种机制使得在进行数据重建时,可以调用集群中所有可用的 SSD 和 VAST Server 资源进行联合重构操作。一个大型的 VAST DataStore 系统通常包含数十台 VAST Server,能够分担恢复负载,从而显著缩短重建时间。
A Fail-in-Place Cluster
随着存储系统扩展到数百块 SSD,设备故障变得不可避免。VAST 系统的设计允许 SSD 在故障后原地保留(fail-in-place),即便同时发生多个 SSD 故障,也无需立即更换设备即可完成重建。在任何时候,VAST 系统写入的纠删码条带都会比系统中 SSD 的总数略窄,从而预留出空间用于未来的重建操作。
在拥有超过 160 块 hyperscale SSD 的大型 VAST 集群中,系统可以利用那些未参与原始纠删码条带的 SSD 上的空闲空间,完成多个驱动器故障后的数据修复。而在较小的集群中,系统会选择写入更窄的纠删码条带。无论哪种情况,只要系统中还有足够的可用空间,VAST 就能持续运行,并保持对额外四块 SSD 故障的冗余保护能力。
VAST Checksums
为了保护用户数据免受 SSD 内部可能发生的静默数据损坏(silent data corruption)影响,VAST DataStore 为系统中的每个数据块和元数据块都维护了一份校验和(checksum)。这些校验和采用 CRC(循环冗余校验) 算法,根据数据块或元数据结构的内容计算而来,并存储在描述该数据块的元数据结构中:一个文件夹内容的校验和存储在其父文件夹的元数据中;一个文件范围(extent)的内容校验和则存储在该 extent 的元数据中;依此类推。
当系统读取某个数据块时,会重新对该数据块进行 CRC 校验计算,并与元数据中保存的校验值进行对比。如果两者不一致,系统会利用本地可解码(locally decodable)的冗余校验数据来自动重建损坏的数据块。
相比之下,一些传统系统如遵循 ANSI T10 数据完整性字段标准(T10-DIF) 的方案,将校验和存储在与数据本身相同的块中,这种方式只能防止 SSD 内部发生的比特损坏(bit rot),但无法防止系统内部数据路径(如 LBA 地址传输)中的错误。例如,在 T10-DIF 方案中,如果系统从 SSD 读取数据的过程中出现一个 1-bit 的地址传输错误,导致将原本要读取的逻辑块地址(LBA)33547 错误地变成了 33458,那么 SSD 会返回 LBA 33458 的数据和其对应的校验和。由于这两者确实匹配,系统无法发现错误,但实际上返回的是错误的数据。
为防止系统中存储的数据因比特错误逐渐积累而导致损坏,VAST 系统会定期运行后台数据清洗(scrub)任务,对整个系统中的数据内容进行全面检查。与附加在 VAST 可变长度数据块上的 CRC 校验不同,系统还为每个 1MB 的闪存子条带生成了一套额外的 CRC 校验码,从而能够快速完成后台清洗操作。
这第二层 CRC 校验机制很好地解决了一个现实问题:客户可能会在系统中存储数百万甚至数十亿个 1 字节的小文件。在传统存储系统中,这种极端的小文件场景会大大拖慢数据完整性检查的速度,而 VAST 的后台清洗机制则可以不受文件或对象大小影响,始终保持高效、稳定的性能。
Rack Scale Resilience via Enclosure HA
尽管 VAST 架构本身具备高度的弹性设计,不存在单点故障,但单个机柜中的设备仍可能因电力或网络中断而导致服务不可用。为应对这类风险,大规模 VAST 系统可以通过启用高可用(HA)选项来提升整体可用性,即使整台存储机柜失效也能保持系统在线。
例如,在一个包含 15 个存储机柜(enclosure)的 VAST 系统中,常规情况下会使用 146 条数据条带加 4 条校验条带(146+4)的纠删码布局,这样的设计带来的存储开销仅为 2.7%。但由于每个机柜通常承载多个条带的片段,一旦其中任何一个机柜下线,系统就会丢失超过纠删码容忍的数量(最多可容忍 4 条丢失),导致系统整体离线。
而采用 HA 方案的 VAST 集群则会使用更窄的纠删码条带设计——每个纠删码条带仅在每个机柜中写入 2 条片段。以同样的 15 个机柜为例,系统会采用 22 条数据条带加 4 条校验条带(22+4)的布局,这将存储开销提升至 15.4%。但好处在于,即使有一个机柜发生故障,仅会导致每个纠删码条带丢失 2 条片段,而 VAST 所采用的“局部可解码纠删码(locally decodable codes)”能够从最多 4 条缺失数据中恢复原始数据,因此系统能够在机柜失效的情况下继续正常服务,无需中断。
Encryption at Rest
开启 “静态数据加密”(Encryption at rest)功能后,VAST 系统会在数据写入存储级内存(SCM)和超大规模 SSD(hyperscale SSD)时,使用通过 FIPS 140-3 验证的加密库对所有数据进行加密。这是一个系统级别的选项,一旦启用,全系统数据都将自动加密。
尽管 Intel 的 AES-NI 微码指令集可以加速 AES 加密运算,但加密和解密操作依然会显著占用 CPU 资源。而传统存储架构(例如某些始终使用每节点 15 块 SSD 的横向扩展文件系统)在扩展容量的同时也被迫等比例扩展计算资源,导致它们在加密数据的同时往往无法保持性能达标,因为 CPU 资源不足。
为了解决这个问题,传统厂商通常依赖 “自加密硬盘”(SED:Self-Encrypting Drive)。这类硬盘把加密任务从主控 CPU 转移到 SSD 控制器中执行,但这种方案的代价是显著更高的采购成本,因为企业级 SED 的售价远高于普通 SSD,而且选择范围也更有限。
VAST 选择了一种更灵活且经济高效的路径:在软件层面对数据进行加密,从而可以继续使用低成本的通用 SSD,而无需依赖昂贵的自加密硬盘。VAST 的 DASE 架构支持用户通过简单地增加 VAST Server 来提升系统的总体计算能力,从而应对加密带来的额外 CPU 负载。
The Logical Element Store Layer–Building Elements from Data Chunks
正如我们前面所看到的,VAST DataStore 的物理层以颠覆性的方式重新定义了传统由逻辑卷管理器、RAID 控制器和 SAN 阵列所承担的设备管理与数据保护功能,从而实现了前所未有的扩展性与效率。同时,VAST 的 Element Store 是一个“超级命名空间”,被广义抽象出来,可同时存储结构化与非结构化数据。
值得注意的是,VAST DataStore 的物理层与逻辑层之间的集成程度远远超过传统架构中逻辑卷管理器与文件系统/对象命名空间之间的关系。在传统架构中,RAID 系统通常只是向上层文件系统呈现出一组虚拟卷,文件系统只能通过这些虚拟磁盘的逻辑块地址(LBA)来访问存储介质。
Element Store 层的元数据提供了结构化的信息,用于将物理层中存储的数据块组织成不同类型的 Element(元素)。由于 Element 的元数据直接管理的是逻辑数据块,而不是传统虚拟磁盘上的块,因此 Element 层与数据块管理层(Chunk Layer)之间的集成远比传统的卷管理器和文件系统更加紧密。
每个 Element 都由其元数据以及用于访问它的方法或协议所定义。VAST DataStore 的目标是实现“通用存储+通用访问”,也就是说,用户可以通过任意协议以最方便的方式访问他们的数据。为此,Element Store 为每个 Element 维护一组抽象的元数据属性,这些属性包含了支持各种访问协议所需的元数据。
这种设计使得系统运维人员即使从未以 S3 对象的形式访问某个 Element,也可以为其添加 S3 元数据标签,比如为数据库表或通过 NVMe over Fabrics 访问的卷打标签。例如,一所大学可以为某些 Element 打上“拥有者=Dr. Doofenshmirtz”的标签,当这位博士因被捕入狱而离职时,管理员就可以快速通过 VAST Catalog 查询出他所有的数据资产。
VAST Element Store 管理三种类型的数据元素:
-
文件/对象(File/Object):文件或对象类型的 Element 是以数据块串(data chunks)的形式存储在系统中的。
它们可以通过标准协议如 NFS、SMB 和 S3 来访问。这是最常见的非结构化数据类型,用于存储各种文档、图片、媒体文件或对象存储内容。
-
卷(Volume):卷类型的 Element 和文件/对象类型一样,也是以数据块串的方式存储。但它们具有额外的访问控制列表(ACL)和身份验证元数据。
这类 Element 通过 NVMe/TCP 协议访问,这是一种现代高性能的块存储协议。适用于需要高吞吐量和低延迟的块设备场景,如数据库、虚拟机磁盘等。
-
表(Table):表类型的 Element 用于存储结构化的表格数据,并采用列式格式(columnar format)进行组织。
这类 Element 通过 SQL 查询访问,类似于数据库中的表结构,适用于数据仓库或分析类工作负载。
我们习惯上将文件和对象称为非结构化数据,而把数据库管理系统中的数据视为“结构化数据”。但在 VAST Element Store 中,非结构化的真正含义是:这些 Element(元素)的内容对 VAST 数据平台来说是不可解析的、不透明的。系统可以对这些数据进行压缩、指纹识别和去重,但如果用户希望深入理解这些 Element 的内容,必须依靠系统外部的工具来完成。相比之下,结构化数据指的是系统能够识别其内部结构的数据类型。VAST 平台能够理解这些 Element 的内容结构,并能直接访问和分析其中的信息,从而提取洞见。
Inherently Scalable Namespace
用户长期以来一直在与传统文件系统的扩展性限制作斗争,原因多种多样,比如:当访问包含数千个以上文件的文件夹时,元数据处理速度显著变慢;有些系统还面临 inode 预分配的限制,这会限制整个文件系统中可存储的文件总数。这些限制正是 2000 年代初对象存储系统兴起的主要推动力之一。对象存储摆脱了将元数据存储在 inode 和嵌套文本文件中的传统方式,因此可以在不牺牲性能的前提下,扩展到数十亿个文件和数 PB 数据。
VAST DataStore 为采用对象或文件访问方式和 API 的应用程序提供了对象存储所承诺的几乎无限扩展能力。随着更多设备机箱(enclosure)加入 VAST 集群,DataStore 的 V-Tree 结构可线性扩展,并通过一致性哈希在各个机箱间自动分布 V-Tree,而不会受到对象大小、数量或分布的显式限制。
Discovering a New Element – The Table
我们一直称由 VAST Cluster 创建和呈现的命名空间为 Element Store,是因为 VAST 的 Element Store 能同时兼容文件系统的层级结构和对象存储桶的扁平结构,其中“Element”这个词既代表文件也代表对象。虽然文件和对象通过不同的协议访问,但它们在 VAST 系统中本质上都是不透明的容器,系统并不了解其内部结构。
VAST DataStore 使用 B-Tree 结构来构建 File/Object 类型的元素,它们本质上是物理层中所述数据块的简单列表。而存储表格的 Element 则有所不同,因为 VAST 数据平台能够理解表的内部结构。尽管表格类型的 Element 的元数据仍然负责将表的内容映射到物理层的数据块,但与 File/Object 类型按字节偏移顺序映射数据不同,Table 类型的元数据是按照“行-列”维度将表格内容映射到对应的数据块。
由于这些元数据存储在 VAST DBox 中的共享非易失性内存中,它可以被 VAST 集群中的所有 CNode 访问和共享。这意味着系统不需要专门的元数据服务器或额外的元数据集群管理,从而避免性能瓶颈,使单个 VAST 集群可以轻松扩展到 EB 级别的数据量。同时,这也使得 VAST DataStore 具备完整的 ACID 特性(原子性、一致性、隔离性、持久性),不仅可以支持关系型数据库所要求的事务一致性,也能提供足够的查询性能,实现类似“几秒钟内为你推荐一部电影或酒店”的应用体验。
更具体地说,VAST DataStore 会将表格数据以列式结构划分为多个压缩后的数据块,组织方式类似于 Parquet 文件,但粒度更细。每个数据块包含表中一个或多个列在一个 row group(行组)中的值。同时,系统会将这些列的统计信息存储在表的元数据中以及每个数据块的结尾(chunk footer)中,以加速后续查询操作。
由于 VAST DataStore 直接以原生表格(表)形式存储数据,用户无需再手动将表划分为适合的大小以优化磁盘型对象存储系统所擅长的大顺序读取。这种看似“反直觉”的设计——将数据存储与数据布局功能整合到同一个 VAST DataStore 中——实际上大大减轻了数据科学家在设计表布局时为适配底层存储限制所需承担的工作负担。
如果数据存储在 S3 数据湖中的 Parquet 文件中,并采用推荐的 128MB 到 1GB 行组大小,那么像 Spark、Trino 等查询引擎就必须先读取桶中所有 Parquet 文件的 footer(尾注信息),再根据这些 footer 中的统计信息过滤掉不符合条件的行组,然后再读取平均 512MB 左右的数据用于处理查询。而在 VAST 的架构中,这类笨重的分片与扫描操作变得不再必要。
VAST DataBase 在处理查询时,可以仅通过读取元数据存储来完成整个 footer 扫描阶段,而无需访问任何实际的数据块。由于其数据块体积远小于标准的 Parquet 行组,因此当系统识别出哪些行组包含感兴趣的数据时,所需读取的数据量也大幅减少。此外,VAST 的 footer 是逻辑结构的,这意味着它是可扩展的——用户可以根据自身查询需求,向 footer 中添加额外的统计信息,从而进一步加速常用查询操作。这样的设计不仅提高了性能,还为个性化优化提供了灵活性。
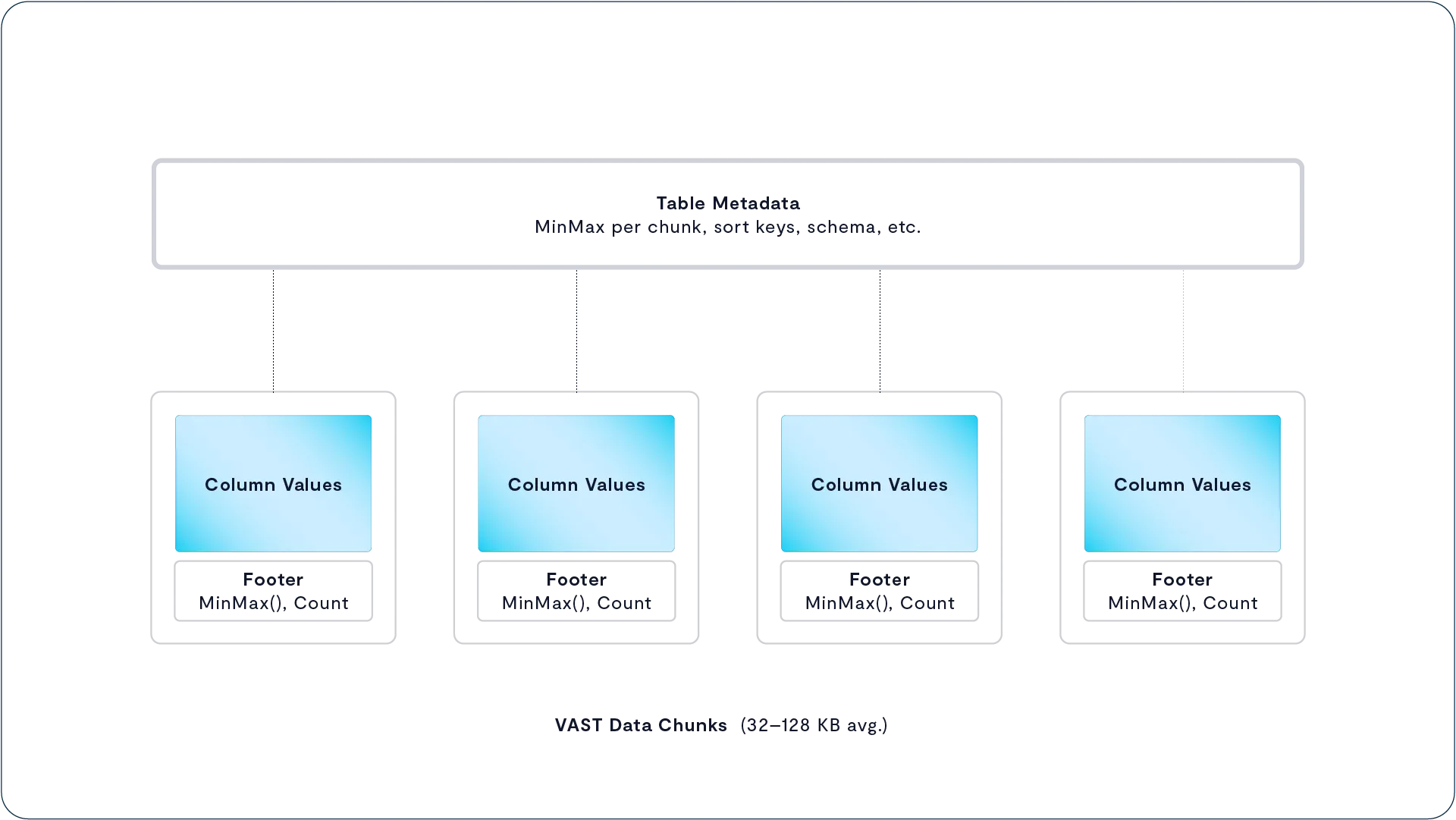
VAST 数据平台将“表”视为一种特殊的 Element 类型,这只是其深度集成能力的一个体现。在传统数据管理平台中,通常是将多个独立组件拼接起来使用——例如数据库引擎负责在文件中构建结构,但这些结构信息并不会传递到文件系统层,因此底层对结构数据一无所知。而 VAST 数据平台则完全不同,它使用统一的元数据系统,来贯通地管理结构化数据:从表中的某个具体字段,到包含这个字段的表元素(Element),再到实际存储该字段数据的数据块,最终精确定位至 SSD 上的某个物理地址。这种一体化的数据结构感知能力,是传统平台无法实现的。
Element Store Data Services
传统的存储系统通常是在卷(Volume)或文件系统级别提供数据服务,比如快照和复制功能。这种架构迫使用户为了满足不同数据集的服务等级需求,不得不创建多个文件系统来分别管理。
VAST DataStore 则创建了一个统一的命名空间,用户无需再管理像卷或文件系统这样的中间抽象层。相反,VAST DataStore 能直接为其 Element Store 中的任意文件夹或对象桶(Bucket)提供快照、复制等服务。
Low-Overhead Snapshots and Clones
写入空闲空间(write-in-free-space)架构特别适合用于实现高性能的快照功能,因为系统可以通过一个全局计数器跟踪所有写入操作,同时轻松维护新旧或已失效的数据状态。VAST 引入了这种全新的架构,使得快照操作变得轻松高效,避免了传统快照方式中常见的数据或元数据复制开销。
VAST Element Store 在设计之初就刻意避免了传统快照机制中的多个缺陷,并为 VAST DataStore 用户带来了诸多优势。
- VAST 快照使用数据与元数据的零拷贝(zero-copy)机制,最大程度减少了因存储或删除快照而带来的性能负面影响。
- VAST 快照无需预留专用的快照空间。它们可直接使用系统中的任意空闲空间,因此相比传统架构更加灵活、高效地利用存储介质。
- 即使系统中存在大量活跃快照,VAST 集群的整体性能影响也几乎可以忽略不计。
在 VAST 中,每次创建快照时,并不会像传统系统那样复制整个卷的元数据副本。相反,VAST 的快照技术深度嵌入在其元数据结构中。VAST Element Store 中的每一个元数据对象都会带有一个名为 snaptime 的时间戳。这个 snaptime 是一个全局系统计数器,从 VAST 集群安装开始计数,并由集群内所有 VAST Server 同步维护,大约每分钟递增一次。
与数据一样,VAST Element Store 中的元数据永远不会被直接覆盖。当应用程序对文件或对象进行覆盖时,新的数据会写入 SCM 写入缓冲区中的空闲空间。系统会为这些新数据创建一个物理地址指针,并将该指针链接到定义该对象的 V-Tree 元数据结构中。
秉承 VAST 一贯的高效设计理念,VAST 的快照与克隆功能建立在物理层的小数据块(平均大小为 16–64 KB)之上。相比之下,许多传统存储系统的快照操作通常是以 1 MB 或更大的页面为单位,这使得 VAST 的快照粒度更加精细,空间利用率更高。
当你在 VAST Element Store 中创建快照时,系统会保留该保护路径下最新的元数据指针版本,以及这些指针所引用的数据块,直到快照被删除为止。快照呈现的数据实际上是由那些 snaptime 早于快照创建时间的最新元数据指针所组成的内容。
由于 VAST 快照机制基于全局同步的 snaptime(快照时间戳),同一时间点创建的所有快照在整个集群中都是一致的。这意味着用户无需像传统系统那样单独定义“一致性组”(consistency groups),只需为所有需要一致性快照的数据路径设置一条统一的保护策略即可实现一致性备份。
当系统执行垃圾回收(Garbage Collection)时,它会删除不再是某个元数据指针的最新版本,且没有被任何快照引用的那些指针,以及仅被这些指针使用的数据。
当然,用户也可以通过调用系统的 REST API 或使用图形界面(GUI)手动创建快照(GUI 实际上也是调用 REST API 实现的)。不过,大多数快照是通过保护策略(protection policies)来自动管理的。
一旦设置好保护策略,VAST DataStore 会在每个受保护路径的根目录中呈现一个名为 ./snapshots 的系统文件夹。该文件夹中会包含每个快照的子目录,并提供对快照内容的只读访问权限。一些 VAST 客户会利用 ./snapshots 目录功能,为其用户提供自助恢复(self-service restore)能力。
Truly Independent Clones
VAST 克隆功能通过创建快照内容的独立副本,为用户提供对快照的快速读写访问。当 VAST 管理员通过 RESTful API 创建某个快照的克隆时,系统会在后台将该快照的内容复制到指定目录中。
新目录及其内容会在几秒钟内呈现,并立即可用于读写操作。在克隆过程进行中,来自克隆目录的读取请求会由原始快照响应。由于 VAST DataStore 只保留每个数据块的一份副本,这些克隆在存储系统中实际上不占用额外空间。
管理员可以选择执行完整的后台复制,将快照的全部内容复制到克隆中;也可以选择“惰性克隆”(lazy clone)方式,仅在数据被访问时再进行复制。惰性克隆极大减少了实际需要复制的数据量,从而降低了对系统性能的影响,尤其适用于挂载多个克隆以寻找“最后已知良好时间点”的场景。一旦后台复制完成,新目录将拥有一套完全独立的元数据结构(尽管它与原始快照的元数据都指向 VAST DataStore 物理层中的相同数据块)。
Indestructible Storage Protects from Ransomware and More
如今用户面临越来越复杂的敏感数据攻击手段。快照可以防止普通用户加密或删除数据,但现代勒索软件的攻击更加高级,它们会获取管理员、root 或超级用户权限,在攻击主数据之前或同时删除快照与备份。
VAST 的“不可销毁快照(Indestructible Snapshots)”能有效防范此类高级攻击,甚至应对拥有高权限的攻击者(如变节的系统管理员)。一旦设置,这类快照在到达预设的过期时间之前,无论攻击者拥有多高的权限,都无法将其删除,从而为用户的核心数据增添最后一道防线。
要创建不可销毁快照(Indestructible Snapshots),用户只需在创建快照时勾选“Indestructible”选项即可。可以通过以下三种方式完成该操作:在图形界面(GUI)中设置、在备份任务脚本结尾通过 REST API 调用、或直接在保护策略(Protection Policy)中定义。
一旦创建了不可销毁快照,该快照即变得不可更改且无法删除——即使是具备 root 权限的超级管理员,也无法修改相关策略或删除该快照。
虽然对企业 CISO 而言,“绝对不可删除的快照”听起来极具吸引力,但在现实中,客户可能会面临必须删除不可销毁快照的情况(例如空间不足)。在这种情况下,VAST 支持团队可以为用户提供一个“限时令牌”,暂时允许删除这些快照。
不过,这种限时令牌的发放是有严格流程的:只有经过预授权的客户代表,在满足客户预设的认证条件后,才能获得该令牌。例如,客户可以要求由七位指定人员中的三人共同发起请求,或要求通报一段特定的口令短语,或者使用其他合理的方式来验证申请人身份并确认这是紧急情况。
Protection Policies Unite Snapshots and Replication
VAST 用户当然可以通过系统的 REST API 或图形界面(GUI)按需创建快照,GUI 实际上也是调用 API 接口来完成操作的。但快照的真正优势在于定期自动创建和统一管理。
VAST 用户通过“保护策略(Protection Policies)”来管理快照的创建计划、保留周期以及在不同 VAST 集群之间的快照复制。保护策略定义了本地快照和远程复制快照的多层次、分阶段的创建与保留规则,所有这些都集中在名为 VAST DataSpace 的管理空间中。
快照的创建与复制频率可以高达每 15 秒一次,远远超过传统系统常见的 15 分钟最小时间粒度。保护策略可以定义多个快照层级,以满足不同时间尺度与保留周期的需求,例如:
- 每 15 分钟 创建一个本地快照(从 12:00:00 开始),并复制到站点 B,两个站点各保留 4 小时。
- 每小时的整点快照(如 13:00:00、14:00:00 等),本地保留 1 周,站点 B 保留 30 天。
- 每天的 午夜快照(00:00:00),本地保留 40 天,站点 B 保留 90 天。
- 每月 1 号中午 12:00:00 的快照,在站点 B 保留 10 年。
由于这些快照都是按照统一的时间计划执行的,因此它们彼此是一致的(例如:月度快照其实就是某次 15 分钟快照中的一个,因此彼此时间对齐、数据一致)。
同一个保护策略可以用于保护多个路径或对象桶(bucket),这使得管理员可以灵活地设定分级保护等级。如上文所述,同时执行的多个路径的快照天生就是一致的,无需额外定义什么一致性组(consistency group),简化了操作,提升了可靠性。
VAST Replication
虽然快照是任何数据保护方案中的第一道防线,但即使是 VAST 的“不可删除快照”也可能面临整个 VAST 集群损毁的风险。为了防止火灾、洪水、地震、龙卷风、飓风、台风、“鲨龙风暴”甚至蒸汽管道爆炸等灾难事件带来的数据丢失,必须将数据从本地数据中心复制到外部地点。而实现这一目标最有效的方式就是数据复制(replication)。
VAST 系统支持多种复制方法,满足用户在数据保护、可用性和灾难恢复方面的需求:
- Snap-to-Object:将指定文件夹或对象桶中的数据复制到兼容 S3 协议的对象存储中,用于异地数据保护。
- VAST 原生异步复制:利用快照机制,在不同 VAST 集群之间周期性地复制某个文件夹的变更内容。
- VAST 原生同步复制:确保所有写入操作的数据都会被同时写入两个 VAST 集群,从而实现严格的恢复点目标(RPO)为零,即数据在任一集群上的写入都被实时复制,确保一致性。
The Access Layer
Providing Multiprotocol Access to the VAST DataStore
我们已经了解了 VAST DataStore 如何管理一个 VAST 集群的存储介质、数据,以及最重要的——元数据。但一个数据平台(甚至只是一个存储系统)不仅仅是用来“存数据”的,它还必须能够将这些数据提供给用户和应用程序访问,定义并强制执行访问安全策略,同时支持集群管理操作。实现这一切访问与控制功能的,就是 VAST Data Platform 架构中的协议层。
就像 VAST Element Store 是一种命名空间抽象,它融合了现代文件系统的优势、对象存储的可扩展性与扩展元数据能力,并支持对结构化表的统一管理一样,协议层则为 Element Store 中的各类元素提供了一个协议无关的访问接口。
一些厂商为了支持新兴协议(如 S3)、复杂协议(如 SMB),或对原生对象存储来说相对陌生的协议(如 NFS、SMB),通常会将开源项目如 MinIO 和 SAMBA 集成到自己的产品中。虽然这种做法让他们能够勾选“多协议支持”这个功能选项,但实际上这些协议在系统中只是“二等公民”,不是原生集成、也无法获得同等的性能与功能保障。
由于许多存储系统的后端实际上是为某一种协议设计的,因此在多协议之间实现统一的访问控制列表(ACL)变得非常困难,尤其是在后端存储本身不支持诸如“拒绝访问(deny)”等 ACL 概念时,这种困难更为明显。另一个问题是:如果采用开源协议模块,这些模块往往以网关进程的方式运行。即便它们不是直接将 SMB 转换为 S3,也仍然需要对请求进行转换,以适配后端存储格式。而大多数开源模块,甚至部分商业协议模块,本身在可扩展性方面也存在明显限制。
基于以上种种问题,VAST 选择将所有协议开发工作保留在内部完成。这一策略不仅避免了外部模块的各种局限性,也让 VAST 的协议模块能够比标准 API 拥有更深层次地访问 Element Store 的能力,从而实现更高效的数据操作。
VAST 所有的协议模块都是由内部团队开发,彼此是“平等”的原生模块。这得益于 Element Store 所提供的命名空间抽象层,它允许 VAST 后续轻松添加更多文件协议、块协议、大数据协议,甚至是尚未诞生的新协议——只需增加一个协议模块即可。
同时,也正因如此,VAST 系统在所有受支持的协议上都能提供类似的高性能体验。
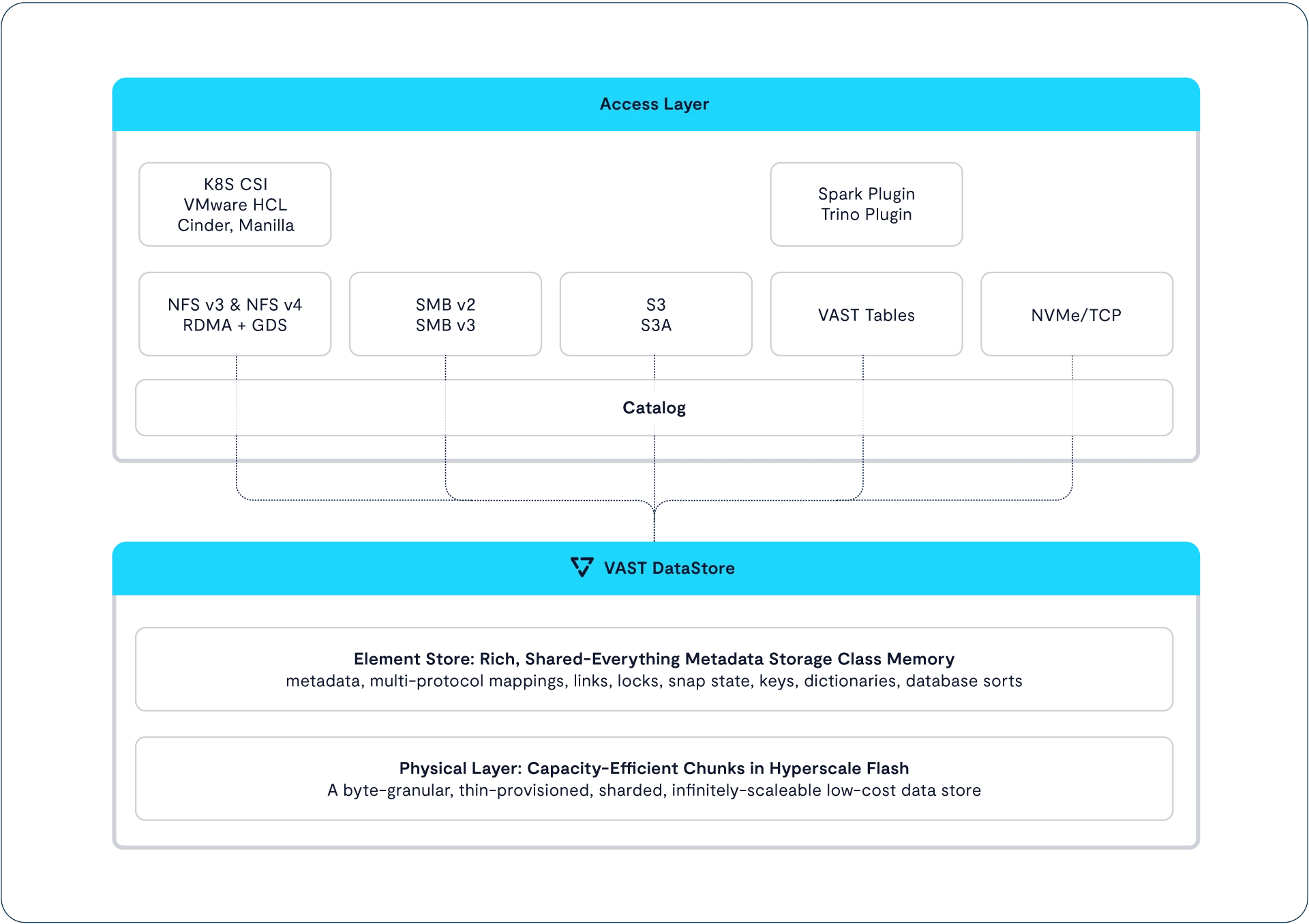
VAST Element Store 中的每一个元素本身都是与协议无关的。这意味着 VAST 集群的所有元素及其全部存储容量,都可以通过任意受支持的协议进行访问。这种设计允许用户在多个协议之间灵活访问相同的数据元素。
以下是一个多协议访问的实际例子:一个基因测序仪通过 SMB 协议将基因组数据写入 VAST;此时,一台 Linux 服务器上的应用程序通过 NFS 协议监听该目录,检测到新文件后立刻调用推理引擎进行处理,并通过 S3 API 写入分析结果作为元数据标签。最终,这些带标签的数据可以通过 S3 协议被上游的云端数据处理流水线调用。
目前,VAST 支持以下协议:
- NFS v3 和 v4.1:用于 Linux 和其他类 UNIX 系统;
- SMB v2.1 和 v3.1:是 Mac 和 Windows 系统上首选的文件访问协议;
- S3:是对象存储领域的事实标准;
- 对于结构化表数据(Table 类型元素),VAST 提供 SQL 接口,并支持 Trino、Spark 等主流大数据分析平台的插件集成。
此外,从 2024 年底开始,VAST DataStore 还将支持 NVMe over TCP,这是一种现代化的块存储访问协议,专门用于访问 Volume 类型的存储元素。
Multiprotocol ACLs
提供真正实用的多协议存储时面临的一大挑战,是如何在 Linux 与其他开源系统的用户(使用 NFS 协议)和 Windows SMB 用户之间,协调非常不同的安全模型。
传统 NFS 遵循的是 Unix 文件安全模型。每个文件都有一个九位的权限掩码(security mask),用来分别为文件所有者、一个用户组,以及所有其他用户(称为“Other”)分配读取、写入和执行权限。这种模型仅支持为一个用户组分配权限,因此在将安全策略与实际业务组织结构对应时存在局限。
为了解决这一问题,Posix ACL(访问控制列表)扩展了灵活性,支持为单个文件或文件夹的访问控制列表中添加多个具名用户和多个具名用户组。
Windows 的 NTFS 文件系统中的访问控制列表(ACL)要精细得多,管理员可以控制用户是否可以列出文件夹中的文件、删除子文件夹,甚至是否有权限更改文件夹对其他用户的访问权限。更重要的是,Windows ACL 支持“拒绝(deny)”属性,可以阻止某个用户或用户组继承来自父文件夹的权限。
NFS 4.1 定义了一种新的 ACL 格式,它的控制粒度与 Windows ACL 类似,但格式又足够不同,从而引入了额外的复杂性。
在与用户沟通的过程中,我们发现,大多数数据集都有一个“主导”的安全视角。例如,一些共享文件夹主要由 Linux 服务器访问,只有少量场景下由 Windows 系统访问。对于这些数据集,用户希望通过 POSIX 或 NFS 4 风格的 ACL 来管理访问权限。
而对于另一些文件夹,主要是由使用 Mac 和 Windows 电脑的人类用户访问的场景,用户则更希望使用 Windows ACL 提供的更精细的权限控制机制,并带来用户熟悉的体验。
正如 VAST Element Store 能够将数据从文件系统和对象存储的表现形式中抽象出来,它同样也将访问控制列表(ACL)以一种抽象的形式进行存储。这些抽象 ACL 可根据客户端所使用的协议,以 Unix 权限位(Mode Bits)、POSIX ACL、Windows ACL 或 NFS 4 ACL 的形式进行强制执行。尽管有了这种抽象机制,SMB 和 NFS 在处理、修改及继承 ACL 的方式上仍存在足够大的差异,因此我们允许用户为系统中的任何视图(View)指定使用 NFS 风格或 SMB 风格的 ACL 视图。
需要注意的是,一个视图所采用的“风格”(flavor)决定了哪种类型的 ACL 是主导的,但与该视图是否以 NFS 导出(Export)、SMB 共享(Share)或两者兼有的方式呈现并无关系,这些是分别独立配置的。
NFS 风格的视图行为完全符合 NFS 客户端的预期。用户可以通过标准的 Linux 工具在 NFS 协议下查询和修改 ACL,而这些设置也将对通过 SMB 和 NFS 协议访问该数据的用户生效。
SMB 风格的视图则像 Windows 共享一样进行管理,用户可以使用 PowerShell 脚本或文件资源管理器(File Explorer)通过 SMB 协议设置精细的 Windows ACL,包括拒绝权限(deny)。这些设置同样会在通过 NFS 或 SMB 访问数据时被系统强制执行。
QoS Silences Noisy Neighbors
大多数 IT 组织历来非常担心某些性能需求极高的应用程序会耗尽存储系统的带宽或资源,从而导致其他应用变慢。
这些高负载应用程序就像数据中心里的“吵闹邻居”——就像你隔壁公寓住了一群整晚放死亡金属的大学兄弟会成员一样,令人头疼。正是出于对“吵闹邻居”的担忧,很多企业不得不建立多个数据孤岛,为不同应用或业务部门配置专属存储,从而避免资源争用。
VAST 系统则提供了多种机制,供管理员使用,以防止这些“吵闹邻居”干扰其他正常运行的应用程序。
在 DASE 架构中,尤其是对于小 I/O 操作,其性能主要取决于可用于处理用户请求的 CPU 资源。因此,管理员可以通过创建服务器池,将一组 CNode 的计算资源专门分配给特定应用或用户群体,从而实现性能隔离。
服务器池为特定用途分配了整套 CNode 的性能资源,但这种控制方式相对粗放,因为每个 CNode 本身就拥有相当大的计算能力。为了实现更精细的控制,VAST 集群提供了更直接的服务质量(QoS)管理机制。
管理员可以为任意视图(即挂载点或共享路径)设定 QoS 限制,控制其带宽和/或 IOPS,并可分别为读取和写入操作设定不同的上限。这些 QoS 限制既可以是绝对值,也可以相对于该视图所使用或已分配的容量进行设定。例如,服务提供商可以定义“每 TB 提供 200 IOPS”的服务等级。
VAST NFS
Parallel File System Speed, NAS Simplicity
NFS(网络文件系统)自 1984 年以来一直是开放系统中标准的文件共享协议。VAST 的 NFS 3 实现包含了多个关键的标准扩展,用于增强安全性(如 POSIX ACLs)和数据管理功能(如 NLM,网络锁管理器)。
传统的基于 TCP 的 NFS 在性能上受到限制,因为 TCP 传输协议在未收到接收端的确认前,只会发送有限量的数据。这种“数据在途量”(有时被称为带宽-延迟乘积)的限制,使得即使在 100 Gbps 网络上,单个 NFS-over-TCP 连接从客户端到服务器的最大吞吐量也只能达到约 2 GB/s。
为了解决这个问题,用户通常采取两种复杂的方法之一:要么配置多个挂载点(从而创建多个连接到 NAS),要么切换到复杂的并行文件系统。
使用多个挂载点虽然可以在一定程度上提升性能,但也带来了更复杂的数据管理开销,而且对于单个应用访问单个挂载点的场景,这种方法并不能带来任何加速效果。而并行文件系统则要求客户端安装专门的文件系统驱动,这不仅限制了操作系统的选择,还使得客户端系统的维护和升级变得更加复杂。
尽管 NFS 已有近 40 年的历史,但这并不意味着它没有经过现代化改进。NFS v4 相较于 NFS v3 引入了更高级的安全模型,提供了更细粒度的访问控制列表(ACL)以及数据传输过程中的加密保护。与此同时,一系列 NFS 协议的性能增强也使 VAST 系统能够在不引入并行文件系统复杂性的前提下,实现媲美并行文件系统的高性能访问。
Accelerating NFS for the AI Era
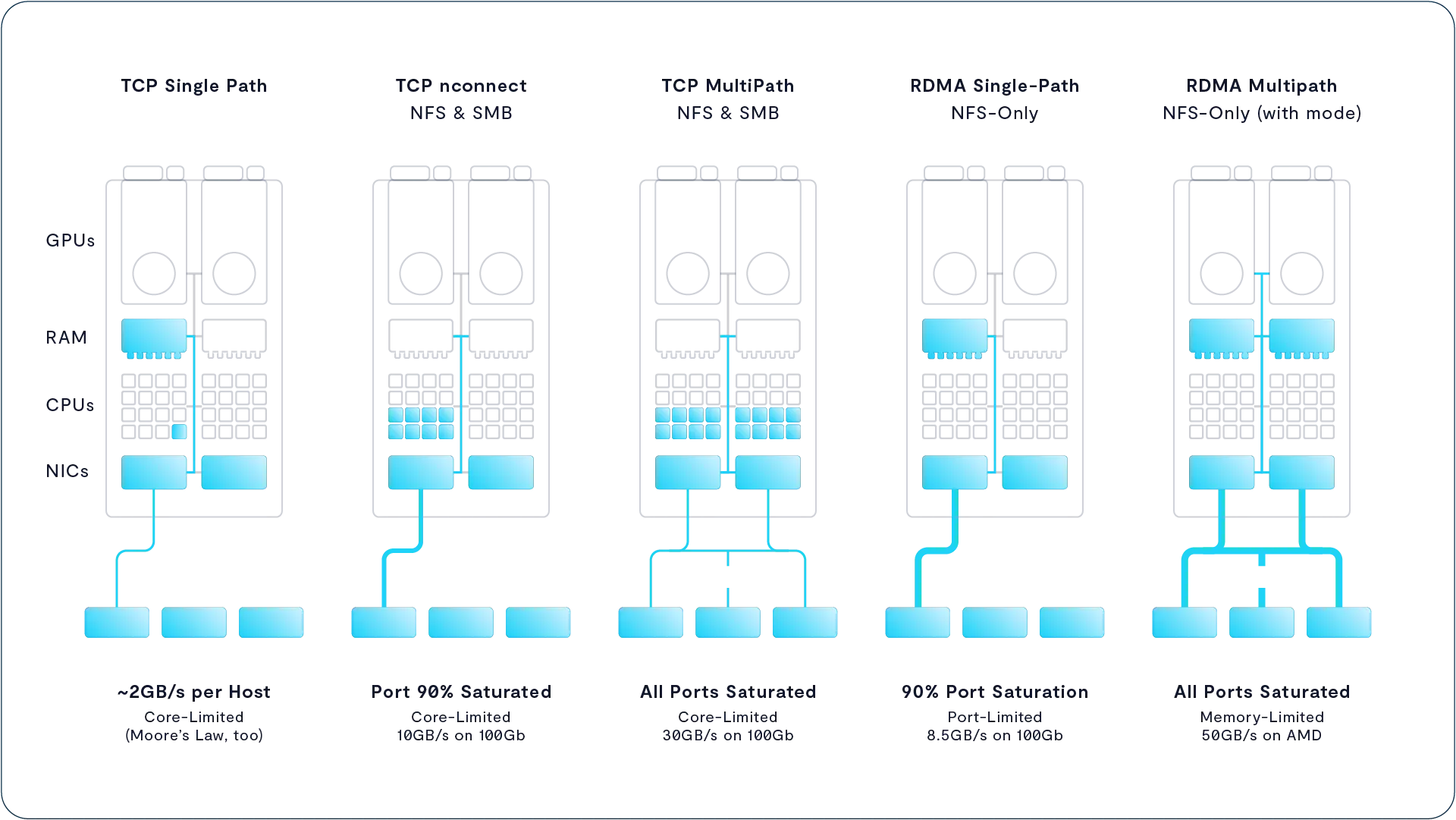
VAST 系统支持三种技术来提升 NFS 客户端主机的访问性能:
- nconnect:这是 Linux 的一种挂载选项,可将单个 NFS 挂载会话分散到多个 TCP 连接上,从而提升并发性能,突破传统单连接的带宽瓶颈。
- Multipath(多路径):在启用
nconnect的基础上,Multipath 能将多个 TCP 连接分布到多个物理网络连接(如多张网卡)上,从而提升吞吐量并增强连接的冗余性与可靠性。 - NFS over RDMA:使用 RDMA(远程直接内存访问)替代传统的 TCP 协议进行数据传输,能够显著降低延迟并减少 CPU 负载,非常适合对时延敏感的高性能计算场景。
nconnect for Multiple TCP Sessions
nconnect 是提升 NFS 性能的第一步,它是 Linux 5.3 内核(于 2019 年发布)中引入的 NFS 挂载选项。当 NFS 客户端使用 nconnect=n 选项挂载某个共享目录(export)时,系统会在 n 条独立的 TCP 会话之间对访问请求进行负载均衡,而不仅仅依赖单一连接。

传统的 NFS over TCP 通常在单连接场景下的性能上限约为 2 GB/s。而启用 nconnect=5 或 nconnect=8 的配置,在 100 Gbps 以太网环境中可以实现高达 10 GB/s 的带宽表现,大幅提升数据吞吐能力。
VAST Adds Multipath
nconnect 挂载选项可以将一个 NFS 客户端与某个挂载点之间的流量分摊到多条 TCP 会话上。正如前文所述,这种方式突破了单个 TCP 会话约 2 GB/s 的带宽上限。然而,这些 TCP 会话仍然是在客户端的单个 IP 地址(即单个物理网卡)与 NFS 服务器的一个 IP 地址之间建立的。
因此,nconnect 带来的性能提升最终仍受到客户端单个网络连接速率的限制。对于配备 100 Gbps 网卡的服务器来说,这种方式非常有效;但如果是使用两块 10 Gbps 网卡的工作站(例如视频编辑工作站),nconnect 就无法充分发挥其潜力,因为它无法利用多张网卡的聚合带宽。
为了解决上述带宽瓶颈问题,VAST 开发了一个开源的 NFS 驱动程序,它可以将由 nconnect 创建的多个 TCP 连接,分布到指定的客户端和服务器 IP 地址列表之间。
例如,假设某个客户端的挂载选项如下:
nconnect=8, ClientIP=10.253.3.17-10.253.3.18, ServerIP=10.253.4.122-10.253.4.125
这意味着客户端有两个可用 IP,服务器有四个可用 IP。该 NFS 客户端会建立 8 个 TCP 会话,将两个客户端 IP 与四个服务器 IP 之间的连接进行组合,最终达到流量分担的目的。下图展示了这些连接的分布方式。

VAST 针对 NFS v3 和 NFS v4 所做的补丁(我们已提交给上游社区,供各大 Linux 发行版采纳)不仅能让视频编辑工作站将流量分布到多个 10Gbps 网络链路上,还能利用每个虚拟 IP 同时向多个服务器地址发送数据,从而将流量分散到多个 CNode 上。
由于 VAST 集群中的共享 SCM 存储承载了全局元数据,它可作为整个系统的一致性来源,这使得多个 CNode 可以并行处理 I/O 请求,同时保持严格一致性。这种架构充分发挥了 VAST 分布式系统的性能潜力。
NFS over RDMA (NFSoRDMA)
在 2010 年代中期,Oracle 及其他关键贡献者联合更新了 NFS 协议,使其支持通过 RDMA(远程直接内存访问)来传输 NFS 的 RPC 请求,从而取代传统的 TCP 传输方式。得益于他们的努力,NFSoRDMA(基于 RDMA 的 NFS)如今已成为所有主流 Linux 发行版的一部分。
RDMA 技术能直接将数据从网络传输到远程计算机的内存中,避免了在 TCP/IP 协议栈或网卡(NIC)内存中反复拷贝数据所带来的延迟。RDMA 的接口称为 RDMA Verbs,这套 API 在 RDMA 网卡(RNIC)上实现,能够将本地内存中的数据直接传送到远程计算机的内存中,同时省去了用户态与内核态之间频繁切换所带来的开销,这些开销在传统 TCP 连接中是不可避免的。
RDMA Verbs 最初是为 InfiniBand 网络开发的,因此 NFSoRDMA 自然可以在标准的 InfiniBand 网络中运行。近年来,RDMA Verbs 也被集成进了以太网的 RDMA 网卡(RNIC)中,使用 RoCE(RDMA over Converged Ethernet,融合以太网上的 RDMA)技术实现。这意味着 NFSoRDMA 不仅适用于 InfiniBand 数据中心,也可在以太网数据中心中部署。
其中 RoCE v2 协议运行在 UDP 之上,不再像早期版本那样对网络配置要求苛刻。除了启用 ECN(显式拥塞通知)之外,RoCE v2 不需要特殊的网络调整。而 ECN 本身自从 10 Gbps 以太网成为主流以来,就已成为企业级交换机中的标准功能。因此,RoCE v2 让在以太网上部署高性能 NFSoRDMA 成为一件简单且可行的事情。
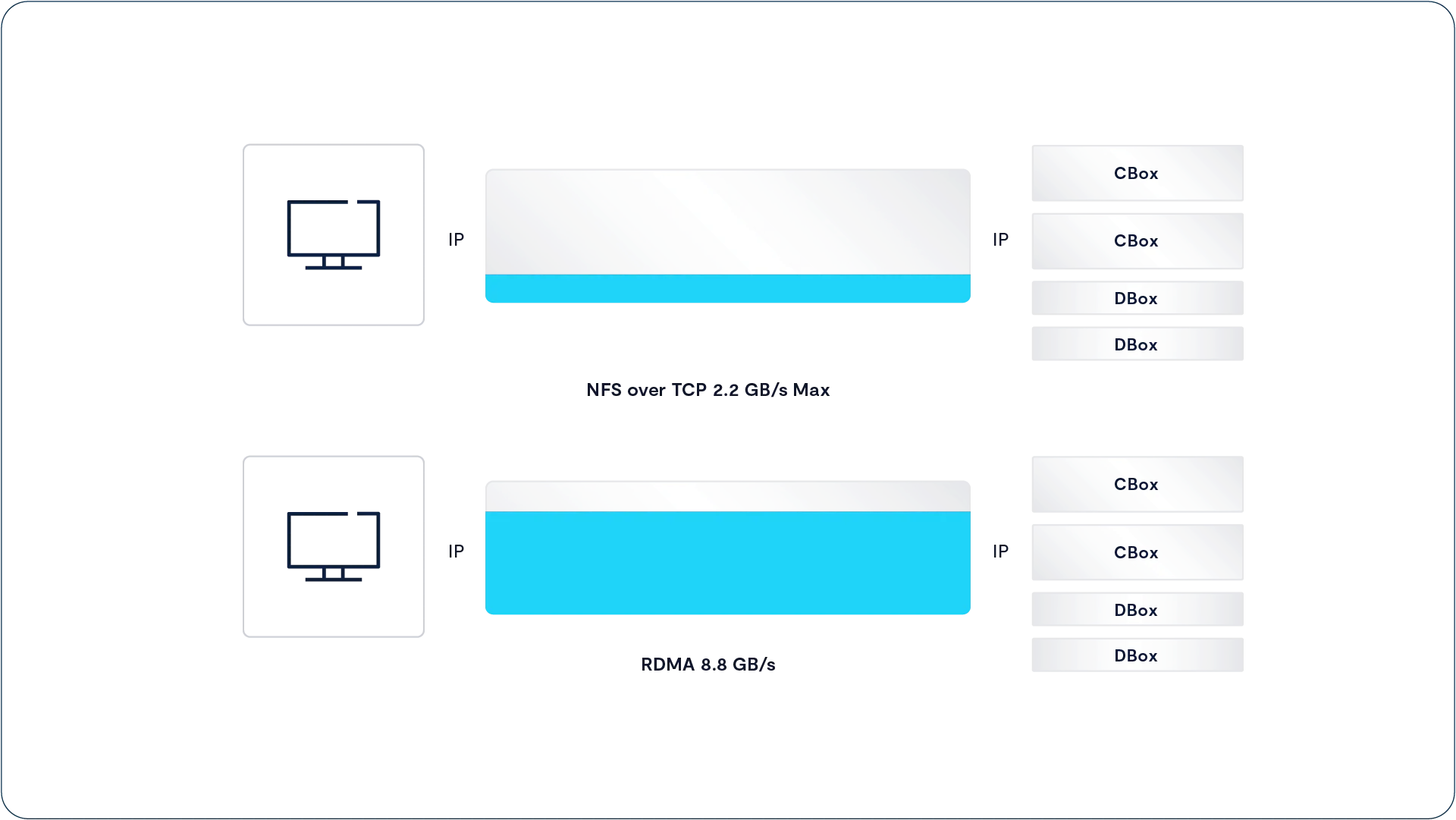
最终的结果是:相比于传统的 NFS over TCP 在连接 VAST 集群时带宽最多只能达到 2 GB/s,一条 NFSoRDMA 会话却可以实现高达 100 Gbps 网络线路速度的约 70%,即 8.8 GB/s 的传输性能。
但 NFSoRDMA 的真正优势还在于其部署的简洁性:NFSoRDMA 客户端已内建于各大主流 Linux 发行版中,无需打内核补丁或安装额外的客户端代理程序,这些通常是部署和维护高带宽并行文件系统时的主要难点。因此,NFSoRDMA 既能提供接近极限的性能,又简化了高性能存储的落地过程。
With VAST NFS Means Now for Speed
过去,由于当时的 NFS 服务器无法满足高性能计算(HPC)、人工智能(AI)以及媒体等工作负载对性能的高要求,用户不得不采用复杂的并行文件系统。
如今,从 nconnect 到 RDMA 的一系列性能增强功能,使得 NFS 成为应对最苛刻工作负载的首选协议。下图展示了每种增强功能如何动用更多主机资源以实现更高性能,其中每次数据传输中参与的活跃组件以蓝色标示。
NFS Extensions
VAST 系统支持多种符合标准的 POSIX 访问控制列表(ACL)扩展。
VAST 是少数几家实现了完全符合 POSIX 规范 ACL 的厂商之一,使系统管理员可以为文件和文件夹定义比传统 Unix/Linux 权限模型更广泛、更细致的访问控制规则。传统模型仅支持为 root、单一用户(文件或文件夹的“拥有者”)以及单一用户组设置读/写/执行权限。而 POSIX ACL 则灵活得多,允许管理员为多个用户和多个用户组分配权限,从而实现更复杂的访问控制策略。
NLM Byte-Range Locking
VAST 的 NFS 实现也支持标准 Linux NFS-util 中定义的 NLM(Network Lock Manager,网络锁管理器)字节范围锁定协议。NLM 定义了一种机制,允许 NFS 客户端请求或释放对 NFS 文件及其内部某个字节范围的锁。NLM 锁属于“建议性锁”,这意味着客户端必须自行检查并遵守其他客户端设定的锁。它支持共享锁和排他锁,适用于那些需要并行访问同一文件多个不同字节范围的应用程序。
VAST 对 NLM 锁的实现天生具备良好的可扩展性,因为锁的管理是完全分布式的,不依赖于单一的集中式锁管理进程。VAST 集群不会设置一个“中心锁管理器”来统一处理所有锁请求,而是将锁信息作为扩展元数据直接存储在每个 V-Tree 文件系统文件中。由于所有系统元数据在整个集群内的所有 VAST Server(CNode)之间共享,每个 VAST Server 都可以直接创建、释放或查询其访问的文件锁状态,无需通过一个可能成为性能瓶颈的中央锁服务器。
NFS Version 4
NFS 第 4 版是对 NFS 协议的一次重大重写,在多个方面(尤其是安全性)相较于 NFS v3 有了显著提升。与 NFS v3(以及 S3)不同,NFS v4 是一种有状态协议,支持通过 Kerberos 实现安全认证,并引入了更细粒度的访问控制列表(ACL)。
VAST 系统支持基于会话的 NFS v4.1,既可运行在 TCP 之上,也支持运行在 RDMA 之上。此外,VAST 还支持 NFS v4 的字节范围锁定、Kerberos 认证、Kerberos 传输加密以及 NFS v4 的 ACL 控制功能。
VAST SMB
File Services for Windows and Macintosh
虽然 NFS 是 Linux 和大多数类 Unix 系统的原生文件访问协议,但它并不是唯一被广泛使用的文件协议。Windows 和 Macintosh 电脑使用的是微软的 SMB(Server Message Block,服务器消息块)协议,而不是 NFS。SMB 协议有时也被称为 CIFS(Common Internet File System,通用互联网文件系统),这是微软曾试图将 SMB 1.0 作为互联网标准提交的一次未成功的尝试。
SMB 是一种非常复杂且有状态的协议,复杂程度导致许多 NAS 厂商选择通过开源的 SAMBA 项目,或是从少数几家销售 SMB 协议栈的商业公司获取相关实现。不幸的是,目前所有可用的 SMB 解决方案在扩展性等方面都存在局限,达不到 VAST 对高性能和大规模集群支持的要求。
VAST 没有采用现成的 SMB 实现,而是选择自主研发 SMB 协议栈,以充分发挥其 DASE 架构的优势。VAST 将 SMB 会话状态存储在集群的共享 SCM(存储级内存)池中,这使得所有 CNode 节点都可以提供 SMB 服务,实现跨集群节点的高可用性和性能扩展能力。由于 VAST DataStore 本身是完全多协议的,SMB 用户可以访问与 NFS 和 S3 用户相同的文件和文件夹。
对 VAST 命名空间中数据的访问是通过 “VAST 视图(View)” 来控制的。VAST View 是一种协议无关的访问抽象,相当于传统 NFS Export 或 SMB Share 的统一表示。管理员可以在同一个 View 上同时启用 NFS 和/或 SMB 访问,并为该 View 设置访问控制的风格(ACL flavor),比如选择 NFS 风格或 SMB 风格的权限控制。
VAST 系统支持 SMB 2.1 和 3.1 协议,并包括对 SMB 多通道(SMB Multichannel)的支持,以提升吞吐性能。
SMB Server Resilience
每当 SMB 客户端在 SMB 服务器上打开一个文件时,客户端和服务器都会分配一个 SMB 句柄(handle)来标识该连接。这就要求客户端和服务器双方都必须保存一份状态信息,用于记录客户端、文件、打开模式和句柄之间的关系。
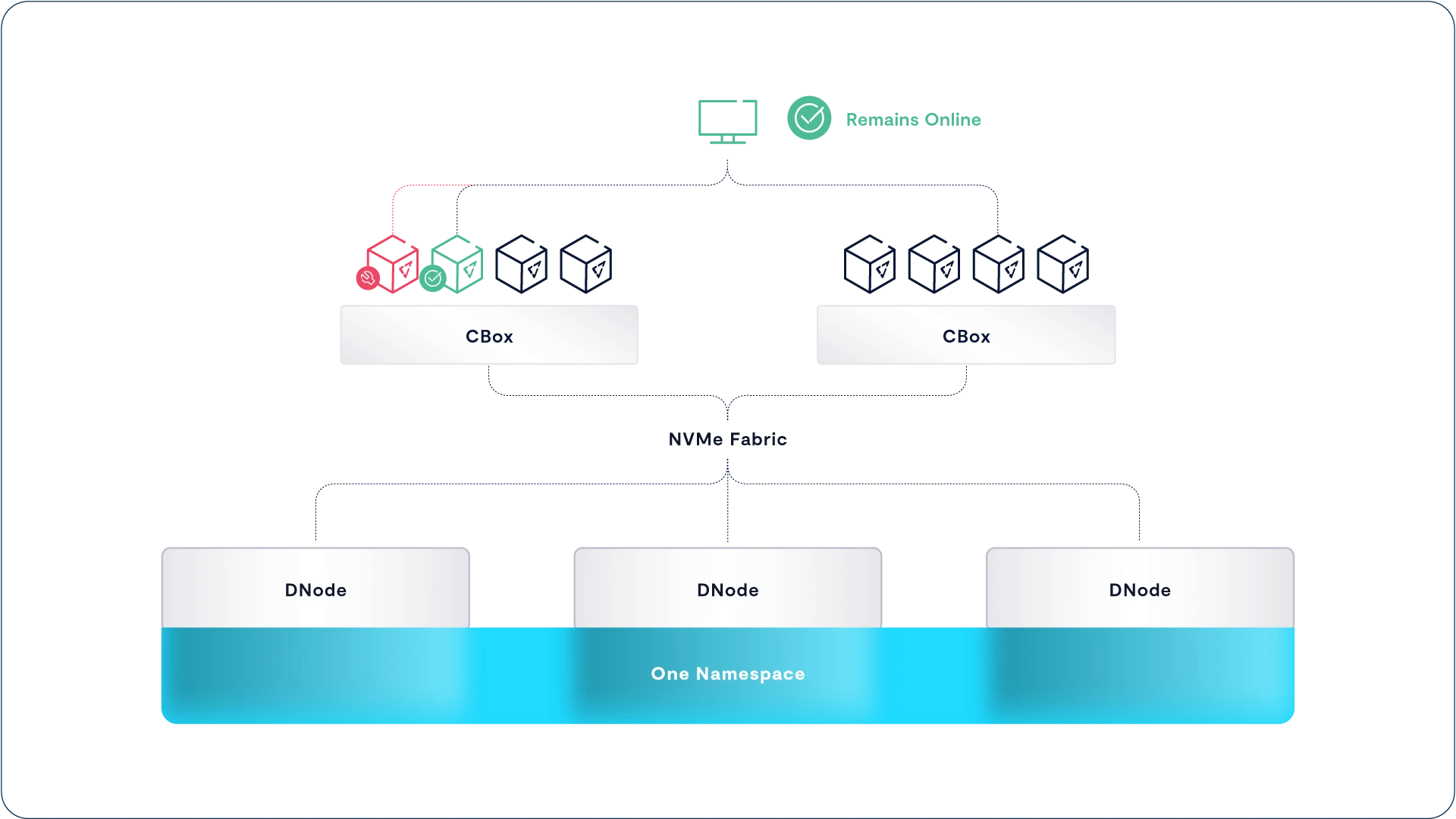
许多可扩展的分布式存储系统在节点发生故障时,会要求用户手动重试或重新连接。虽然另一个节点可能会接管故障节点的虚拟 IP 地址,但动态的状态信息(例如文件句柄)往往无法同步,导致连接无法自动恢复。要实现 SMB 客户端在节点故障后能够自动恢复访问,必须让状态信息在集群中共享,而这种共享需求也暴露了“共享-无结构(shared-nothing)”架构的局限性。
DASE and SMB Failover
在 VAST 服务器中,SMB 客户端与服务器之间的动态句柄、文件租约(lease)以及所有定义其交互关系的状态信息,都会存储在集群 VAST Enclosure 中的共享 SCM(存储级内存)中。这种设计使得当某个 VAST 服务器下线时,集群中其他存活的服务器不仅可以接管它的 IP 地址,还能从 SCM 中读取连接状态,从而无缝地继续处理原有连接。
对于 SMB 客户端来说,这种服务器切换过程看起来就像是一场短暂的网络波动——系统检测到 VAST 服务器故障并迅速完成恢复,这正是 SMB 2.1 中“弹性句柄(resilient handles)”的设计初衷。整个过程中不会丢失句柄,更重要的是,用户和应用程序能够在不中断的情况下继续运行,好像什么都没发生一样。
VAST S3
Object Storage for Modern Applications
Amazon 的 S3(Simple Storage Service)协议,或者更准确地说是 Amazon S3 所采用的协议,已经成为对象存储的事实标准。这一地位的确立很大程度上是因为它使开发者能够同时支持本地对象存储(例如 VAST 的 VAST DataStore)和云存储(如 Amazon S3 及其竞品)。
VAST 的协议管理器(Protocol Manager)通过 HTTP 的 GET 和 PUT 方法来导出 S3 对象,每次请求会传输完整的对象,且基于的是扁平命名空间。每个对象通过 URI(统一资源标识符)进行标识和访问。虽然文件的 URI 中可以包含斜杠(/),看起来像传统的文件路径,但对象存储不会把斜杠视为特殊符号,因此它只是对象标识符中的普通字符。这样一来,系统能够“模拟”文件夹结构,但不会引入层级结构带来的复杂性。
VAST 中的对象(VAST Objects)在存储方式上与文件类似,不同之处在于,S3 对象不仅包含其内容本身,还包含用户自定义的元数据,这使得应用程序能够将与对象相关的元信息直接嵌入对象中进行管理。
传统上,对象存储主要用于归档用途,但随着高速对象访问技术的出现,尤其是全闪存(All-Flash)对象存储的普及,对象存储的使用场景已经大幅扩展。例如,许多大规模并行处理(MPP)系统和 NoSQL 数据库,如今都将对象存储作为其底层的数据存储方式。
NVMe-Over TCP Block Services for the 21st Century
从一开始,文件存储和对象存储系统就是为了提供一个可供多台计算机同时访问的共享存储池而设计的。正是因为有了这种共享机制,那些需要多个服务器协同处理同一数据集的大规模应用程序才能实际运行。
然而,也有一些应用对其数据“占有欲”更强,它们坚持将数据存储在它们完全掌控的磁盘驱动器上,即便是虚拟磁盘驱动器也不例外。这类应用通常属于高度耦合的应用集群,例如某些集群系统只允许其中一个成员访问一个逻辑磁盘;如果某个节点宕机,它们会使用设备保留(device reservation)机制来在成员间转移该逻辑磁盘的所有权。
通俗来说,这类应用要求“谁拥有磁盘谁说了算”,并通过控制磁盘的访问权来维持集群内部的一致性和容错机制。
在过去二十多年里,企业主要通过 光纤通道(Fibre Channel)SAN 来解决上述问题,将服务器连接到价格高昂的存储阵列。这些存储阵列会将其控制的 SSD 和/或 HDD 划分成多个虚拟磁盘驱动器,这些虚拟磁盘在服务器操作系统看来就像是本地连接的 SCSI 设备一样。
Fibre Channel 和 iSCSI 本质上只是用来在服务器与存储控制器之间传输 SCSI 命令的协议。每条 SCSI 命令会从逻辑磁盘(我们仍称其为 LUN,逻辑单元号,即 SCSI 总线上的磁盘地址)上,从某个起始逻辑块地址(LBA)开始读取或写入若干个 512 字节的块。
随着 SSD 技术的不断成熟,业界开发了 NVMe(Non-Volatile Memory express),作为取代 SCSI 的下一代低层命令协议,用于服务器或控制器与 SSD 之间的通信。NVMe 专为 SSD 而设计,充分发挥了固态存储可并行处理多个请求的能力,它用多达 64K 条命令队列 取代了 SCSI 的单一命令/数据队列,极大地降低了访问延迟。
NVMe over Fabrics(简称 NVMe-oF)将 NVMe 协议扩展到了一个具备高可靠性的网络结构(即“fabric”)上,就像当年的 Fibre Channel 和 iSCSI 把 SCSI 协议扩展到了网络上一样。不同之处在于,如今的网络架构比 Fibre Channel 诞生时要“聪明”得多,而 NVMe-oF 正是能够利用这些更先进网络作为传输介质的协议。VAST 的 DASE 架构通过 NVMe over RDMA(远程直接内存访问)实现了集群中 CNodes(计算节点)对 SSD 的超低延迟访问。
如果不能为需要块级存储访问的应用程序、用户和管理员提供服务,VAST DataStore 就无法真正称得上是“通用存储”平台。而 VAST 的理念是摒弃传统路径,因此我们并没有采用老一套的技术手段,而是通过 NVMe over Fabrics——更具体地说,是 NVMe over TCP(NVMe/TCP)来提供块存储功能。
VAST 系统在支持 NFS、SMB 和 S3 等主流协议的基础上,还支持 NVMe/TCP 作为访问协议。通过 NVMe/TCP,用户可以访问存储在 VAST Element Store 中、以 Element 形式存在的 LUN(逻辑单元号)。与 NVMe over RDMA 相比,NVMe/TCP 对网络环境的要求更低,但在许多基准测试中依然能提供相当的性能表现。
目前,几乎所有主流操作系统和虚拟化平台(Hypervisor)都内置了 NVMe over Fabrics 的发起端(initiator),这使得它们能够通过 NVMe/TCP 将 VAST 系统上的 LUN 映射为服务器中的本地磁盘设备。而由于 VAST 集群中的任意 CNode 都可以处理对 LUN Element 的访问请求,因此无需使用传统块存储中常见的 ALUA(Asymmetric Logical Unit Access)多路径驱动程序。用户只需使用操作系统或虚拟化平台中自带的标准多路径驱动,就能获得优异的性能和高可用性。
Ecosystem Integrations
VAST DataStore 专为现代应用与现代数据中心而设计。在这样的数据中心中,资源的分配与管理依赖于通过 API 进行自动化编排,而不是靠存储管理员手动点击图形界面来完成。正如前文所述,VAST DataStore 采用的是“API 优先”设计理念:所有管理功能首先通过 REST API 实现,VAST 的图形界面(GUI)本质上也是调用这些 REST API,就如同客户的自动化平台与脚本一样。
Kubernetes CSI
容器是当前部署应用程序最高效、最现代的方式之一,因此 VAST 自身也采用容器来部署其服务器。Kubernetes(最初由 Google 开发,现由云原生计算基金会 CNCF 维护)已经成为容器编排的主流引擎。它能在一组 X86 架构的服务器节点上,以容器 Pod 的形式自动化地部署和管理基于微服务的应用程序。
随着用户将越来越复杂、对数据要求越来越高的应用程序部署到容器中,容器社区为此引入了「持久卷(Persistent Volumes)」机制,并将其整合进 Kubernetes,从而为这些应用提供可靠的存储支持。通过 CSI(容器存储接口,Container Storage Interface),Kubernetes 可以对接多种类型的存储系统,包括文件存储、块存储以及各类云存储服务。除了 Kubernetes,使用 Apache Mesos 和 Cloud Foundry 的 VAST 用户也可以通过 CSI 接口实现存储的自动化管理。
VAST 的 CSI 驱动程序在 Kubernetes 集群的控制平面与 VAST DataStore 集群之间提供了一个接口。通过这个接口,Kubernetes 集群可以将 NFS Export 中的某个文件夹动态创建为持久卷(Persistent Volume),并为该卷设定配额(Quota)来控制容量,然后将这个卷挂载到对应的容器 Pod 中供其使用。
秉承 CSI 背后的开放与开源理念,VAST 的 CSI 驱动是开源的,任何感兴趣的用户都可以从以下地址获取并使用该驱动:https://hub.docker.com/r/vastdataorg/csi。
Manilla
VAST 的 CSI 驱动为 Kubernetes 集群提供了一个标准化接口,用于为容器 Pod 创建可挂载的持久卷(Persistent Volumes),这些卷以文件夹的形式存在。
VAST 的 Manila 插件则进一步加强了 VAST 集群与开源云平台 OpenStack 之间的集成关系。除了像 CSI 一样能为虚拟机(VM)发布卷之外,Manila 插件还能自动创建 NFS Export,并设置 Export 的访问控制列表(IP 地址白名单)。
通过 Manila,运营规模较大的用户可以实现自动化流程:在 OpenStack 中为每个 Kubernetes 或 OpenShift 集群自动创建独立的 NFS Export,同时借助 CSI 将这些 Export 作为持久卷挂载到各自集群的容器 Pod 中,从而实现完整的多云或私有云自动化存储管理。
GPU Direct Storage
运行人工智能应用的 GPU 服务器所处理的数据量远远超过通用 CPU 所能处理的级别。即便配备多块 100 Gbps 的网络接口卡(NIC),GPU 仍会因为数据传输流程太慢而浪费大量时间:数据必须先从 NIC 的数据缓冲区复制到 CPU 内存中,然后再传输到 GPU 内存中,才能被用于分析。
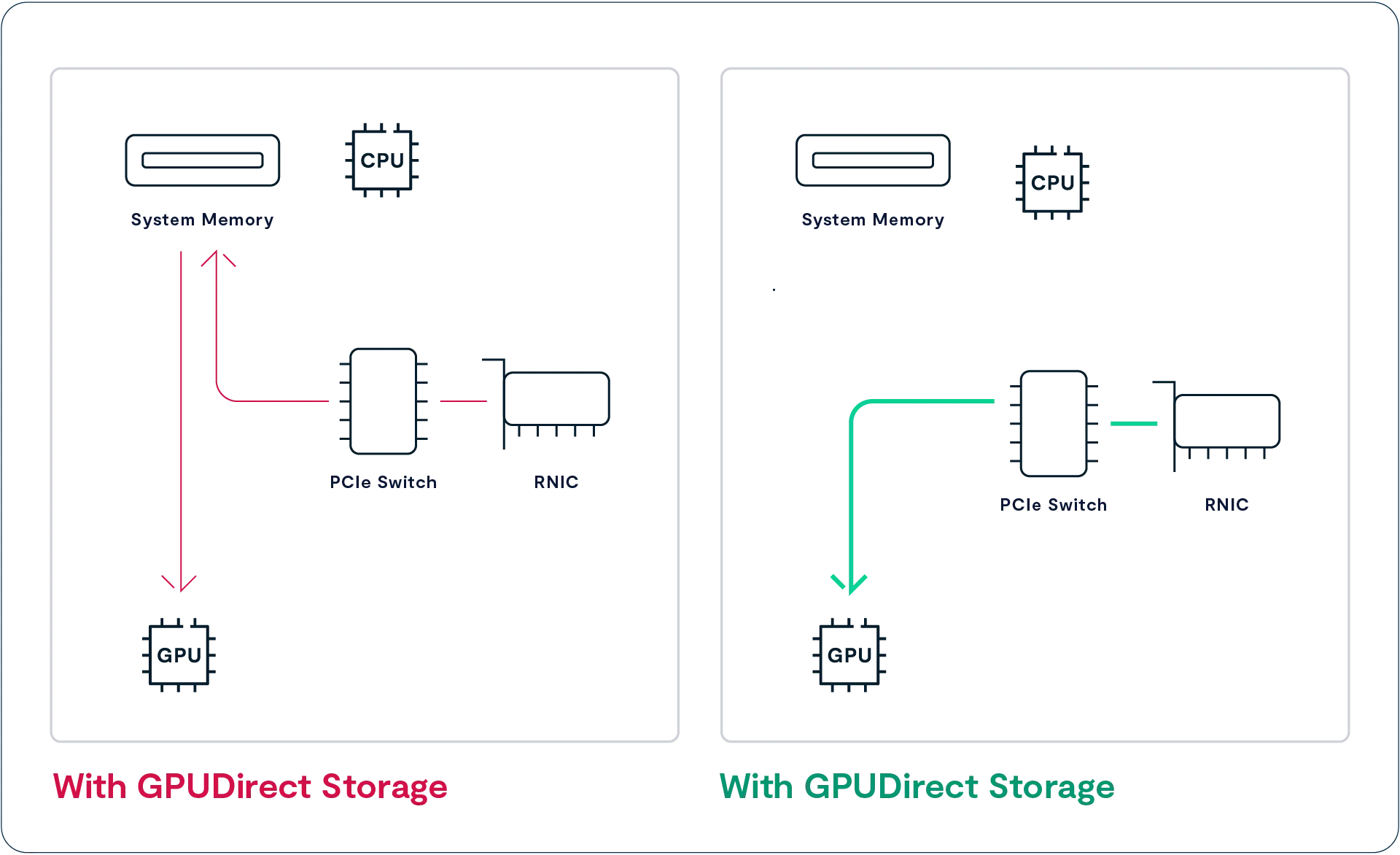
NVIDIA 的 GPUDirect Storage(GDS)通过 RDMA(远程直接内存访问)技术,为 NFS 数据提供了一条从 RNIC(RDMA 网络接口卡)直接传输到 GPU 内存的路径,从而绕过了 CPU 及其内存。GDS 消除了主内存到 GPU 之间 50 GB/s 带宽瓶颈,显著提升了 GPU 可访问的数据量。通过 GDS,服务器可以从多个 RNIC 并行向 GPU 传输数据,使总带宽最高可达 200 GB/s,大幅增强了 GPU 的数据处理能力。
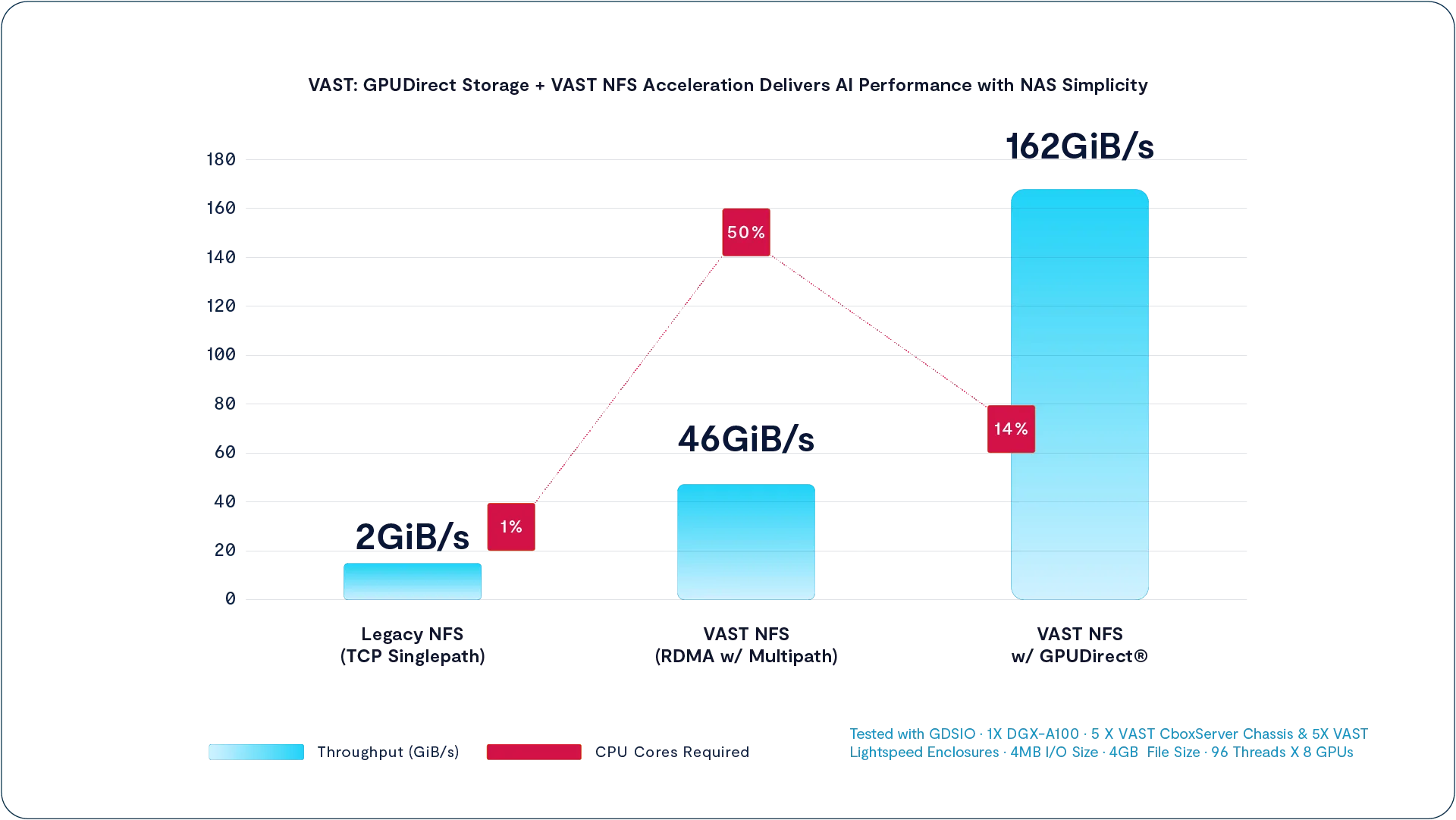
GPU Direct Storage 还显著降低了访问存储的系统开销。在我们对 VAST 集群与 NVIDIA DGX-A100 GPU 服务器进行测试时(如上图所示),将 NFS over RDMA 与多路径负载均衡结合,并利用 DGX-A100 配备的 8 个 200Gbps HDR InfiniBand 接口,已将总带宽从传统 NFSoTCP 的 2 GiB/s 提升到了 46 GiB/s。
但即便如此,通过主内存将所有数据转移到 GPU 依然会占用 DGX-A100 上 128 个 AMD ROME 核心的一半计算资源。
而切换到 GPU Direct Storage 之后,不仅将带宽提升到了 162 GiB/s,更将 CPU 使用率从 50% 降低到了 14%,极大提高了系统效率与可扩展性。
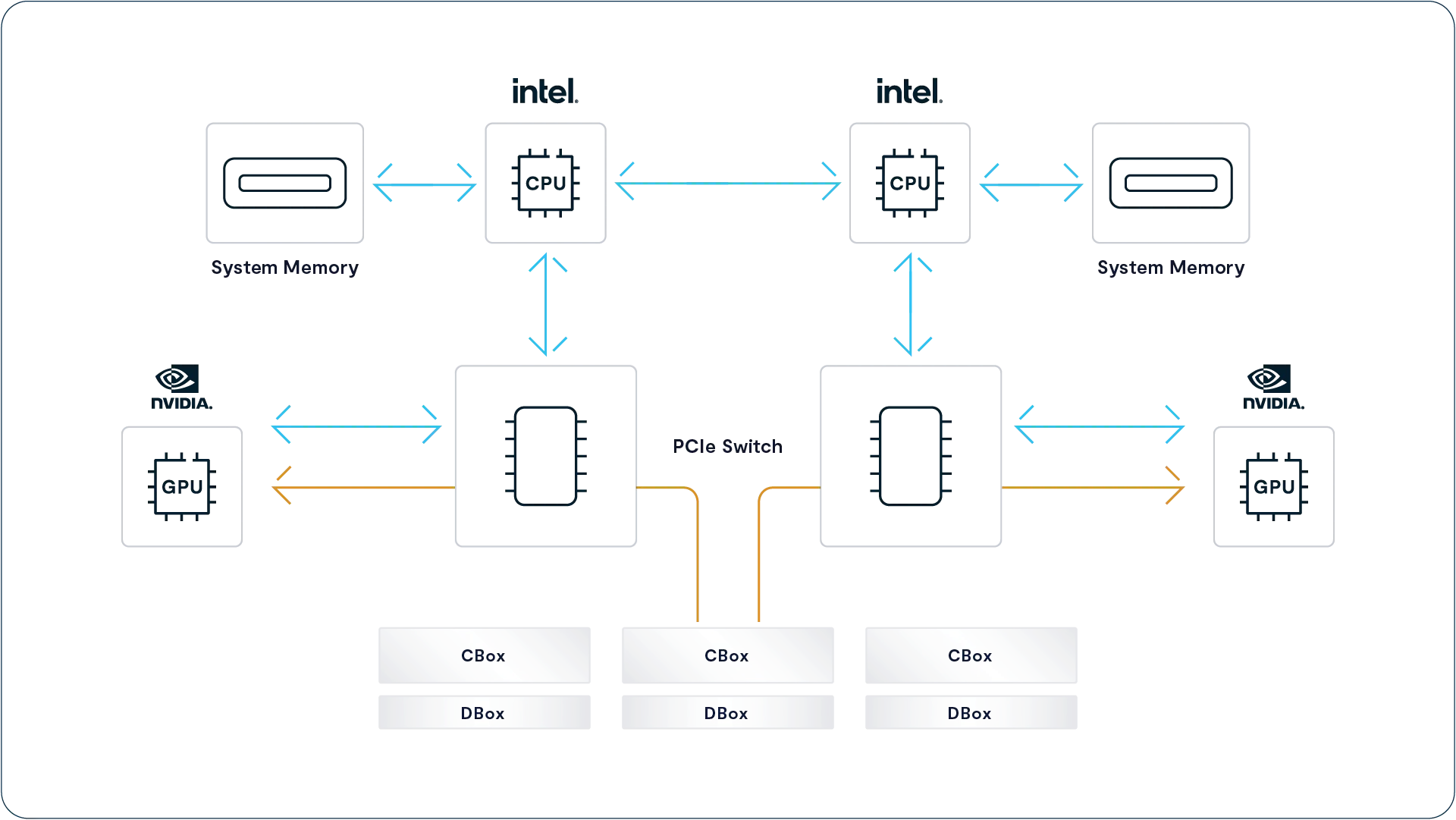
NUMA-Aware Multipathing
现代服务器中的 PCIe 插槽(就像内存插槽一样)是直接连接到两个 CPU 之一的。这导致了一种架构现象,叫做非统一内存访问(NUMA)。在这种结构下,一个运行在 CPU-A 上的进程访问连接在 CPU-A 本地的内存速度要远快于访问连接在 CPU-B 上的内存,因为访问远程内存必须跨越两个 CPU 插槽之间的桥接通道,而这个通道的带宽可能成为性能瓶颈。
GPU Direct Storage 在执行访问时,会通过 RDMA 技术将数据从一个 PCIe 插槽上的 RNIC(远程直连网卡)直接传输到另一个插槽上的 GPU。VAST 的 NFS 多路径驱动是具备 NUMA 感知能力的,它会智能地将来自 VAST 集群的数据流量,分配到与 GPU 处于同一 CPU/NUMA 节点上的 RNIC 上。这样可以避免数据在 CPU 之间来回穿越桥接通道,从而绕开该瓶颈,提高整体的数据传输效率。
Ecosystem Validations
简洁始终是 VAST DataStore 设计的核心原则之一。相比复杂的分层存储架构,只使用一种价格合理的闪存层更为简单;相比 SAN(存储区域网络)和并行文件系统,采用标准的 NAS 协议也更加简洁易用。
支持标准协议也意味着可以更方便地将 VAST 用作各种应用程序的数据存储后端。尽管这些应用使用的是标准协议,但部分软件厂商仍要求对存储系统进行认证或验证,而 VAST 已获得多个主流平台的验证支持,包括:
- VMware vSphere:已通过验证,可作为 vSphere 的 NFS 数据存储使用
- Commvault
- Veritas
- Veeam
- Etc., etc
More to Come
随着 VAST 数据平台在每次新版本中功能的不断增强,其与生态系统的深度集成也变得越来越有可能。我们正与各类厂商合作,利用 VAST Catalog 来替代他们当前所采用的耗时耗资源的文件系统遍历方式。借助这种方式,备份软件、工作流管理器以及其他数据迁移工具将能够快速定位在两个快照之间发生变更的文件,大幅提升扫描效率与整体性能。
NVIDIA DGX H100 SuperPod Validation
NVIDIA 的 DGX SuperPod 是一款专为人工智能打造的工程化超级计算机系统,基于 NVIDIA 针对 GPU 优化的 DGX 服务器构建。最新一代 SuperPod 配备了 127 台 DGX H100 服务器,每台服务器内含 8 块 H100 GPU 和 8 个 400 Gbps 的 InfiniBand 接口。

VAST 是首个(截至目前也是唯一一个)获得 NVIDIA 认证、可作为 SuperPod 实施方案中数据存储系统的 NAS 解决方案。其他获得认证的系统则普遍依赖结构更复杂的并行文件系统。详情可参见 VAST 官方新闻稿:https://vastdata.com/press-releases/vast-data-achieves-nvidia-dgx-superpod-certification。
Enjoy Reading This Article?
Here are some more articles you might like to read next: