Contents
EMSim 是我天津大学博士论文的核心工作。AI 加速扩展 EMSim+(GAN,以及 GAN+TL)和 AIPS 由高亚主导——我指导她的研究并参与共同署名。本文将这一系列工作作为一个整体来叙述。
Why pre-silicon evaluation?
密码集成电路是每个需要建立信任的系统的核心。银行卡用于认证交易;IoT 传感器向网关证明自己的身份;硬件安全模块(HSM)为数据中心的签名基础设施保护密钥。在每种场景中,专用 IC 运行 AES 对称加密或 Kyber 后量子密钥封装等算法,处理永不离开芯片边界的秘密——至少在理论上如此。
侧信道分析(SCA)在不接触算法本身的情况下突破这道边界。芯片计算时会产生功耗、辐射电磁(EM)场,并在因数据而异的时间间隔内完成操作。这些效应都不是有意的输出,但全都携带与芯片内部状态(包括密钥)相关联的信息。能够测量运行设备的功耗轨迹、EM 辐射或时序差异的攻击者,可以从统计上恢复密钥材料——无需利用密码算法数学上的任何漏洞。
统计分析工具已相当成熟。差分功耗分析(DPA)及其推广形式——相关功耗分析(CPA)——将测量 trace 与候选密钥字节下的芯片预期行为模型对比,扫描密钥空间,直到正确假设产生峰值。非特定 t 检验(TVLA)按数据相关准则(如固定明文与随机明文)分组 trace,用 t 检验判断两个分布是否存在差异——若存在,则设备泄漏信息。这一切不需要解决任何数学难题,只需要足够的测量次数和计算量,而两者的成本都很低。
在实际操作中,攻击者的设备并不复杂:一台数字示波器、一个架在芯片封装上的电流探头或 EM 近场探头,以及一台运行开源分析工具的工作站。恢复 128 位 AES 密钥可能需要几千到几十万条功耗轨迹,具体取决于设备的防护措施——这样的采集活动在工作台上几小时内就能完成。EM 测量甚至可以更加局部化,无需开盖即可针对裸片上的特定区域。
传统的应对方式是在芯片从晶圆厂回来后再进行评估,表征其泄漏情况,如果结果不好再重新设计。这种方式越来越难以为继。在先进工艺节点流片的成本高达数千万美元;即便是在较老的工艺节点,费用也相当可观。更关键的是,从设计到硅片需要数月——仿真、版图、验证、流片、制造、封装、调试。如果第一批硅片泄漏,团队必须重走整个流程,同时产品上市时间推迟,而存在漏洞的产品可能已经进入发货流水线。上市时间压力经常将”下一版本修复”变成”加个软件补丁然后出货”。
流片前评估改变了这种经济逻辑。核心思路是直接从芯片设计中仿真物理泄漏——功耗或 EM 辐射——在任何硅片存在之前,使防护措施得到验证,漏洞在流片前就能被发现并修复,设计团队在流片时有证据证明芯片具有抗侧信道能力。在 RTL(寄存器传输级)或版图阶段进行修改,代价是工程师的时间,而非晶圆厂的费用。
The simulation challenge
流片前 SCA 评估必须同时满足两个要求。首先,仿真的泄漏波形必须足够准确,使得针对仿真数据运行的统计攻击能得出与真实硅片相同的结论——如果仿真显示设计存在泄漏,就必须有实际的泄漏机制可以指出。其次,trace 数量必须足够大,才能真正可信地运行这些攻击:CPA 和 TVLA 采集通常需要 100K–1M 条 trace,才能可靠地完成密钥恢复或以统计置信度排除泄漏。这两个要求都与以下四个具体问题正面碰撞。
-
基于物理的 EM 仿真无法扩展到采集规模的 trace 数量。 版图级电磁仿真是严格的起点。它如实建模寄生网络、金属线几何形状,以及决定设计辐射方式和位置的物理机制。但商业 EDA(电子设计自动化)流程是为设计验证构建的,而不是为大规模生成 trace 而设计的:单条功耗轨迹的物理级 EM 仿真在工作站上可能需要几分钟。将这个数字乘以规模:生成 100K 条 trace 需要数月时间,或者任何流片前评估团队都无法承受的计算预算。
-
即便是加速的物理仿真,对完整采集来说仍然太慢。 将单条 trace 仿真时间从几分钟缩短到几秒的速度提升有帮助——但不能弥补差距。即便相对基线提速 32×,100K 条 trace 的采集仍需要数天时间。
-
针对一种设计训练的学习型仿真器无法迁移到下一种设计。 用于泄漏仿真的机器学习模型是针对特定芯片的版图、工艺参数和工作条件进行训练的。当设计改变——不同的密码核、新的防护措施、工艺节点迁移——模型的假设就会失效,必须从头重新训练。在设计迭代循环中,这意味着要在最不合时宜的时刻支付训练成本:恰恰是工程师需要快速了解提出的修复方案是否关闭了泄漏路径的时候。
-
SCA 的功耗仿真与现有 EDA 工具所解决的问题不同。 电磁泄漏是一种攻击通道;功耗是研究最深入的通道,也是大多数设计师首先考虑的通道,因为探头放置更简单,文献更丰富。但设计师已经使用的仿真工具——如 PrimeTime PX 中的波形精确功耗分析——是为回答热设计和电压变化问题而构建的,这些问题关心的是时钟周期内的平均功耗。SCA 攻击依赖于纳秒级瞬态波形,这些波形编码了各个逻辑路径上数据相关的转换。
接下来四节按顺序逐一处理这四个问题,并描述我们各自采取的应对措施。
EMSim — physics, accelerated
版图级电磁仿真原则上是解决问题 1 的正确答案。它从物理现实出发:芯片实际版图的几何形状、真实金属导线的寄生电容和电阻、在每个时钟沿流经每条网线的切换电流。这种级别的仿真能捕捉 RTL 级估算无法捕捉的内容:塑造 EM 探头实际测量结果的空间结构。问题不在于准确性,而在于成本。
商业 EDA 流程是为设计验证构建的,而非为采集规模的 trace 生成而设计。在工作站上通过版图寄生提取网表对单条功耗轨迹进行物理精确的 EM 仿真,可能需要几分钟。这个数字听起来并不令人担忧,直到你将它乘以规模:100,000 条 trace——一次适度的 SCA 评估采集——需要数月计算时间。而日益被泄漏认证所要求的百万条 trace,则将估算时间推向任何合理流片前预算都无法承受的范围。
EMSim 直接攻克这一吞吐量瓶颈,且不放弃物理基础。
出发点是理解 EM 辐射在版图级为何呈现出特定的样子。当芯片进行逻辑状态切换时,时变电流流过金属互连——尤其是在裸片上分配电源电压的顶层电源和地线,以及在层次结构中向下扇出的时钟树。这些电流产生磁场,其空间和时间模式正是近场 EM 探头所采样的内容。版图几何形状决定了磁场:导线长度、方向、与探头的距离,以及它们在每个时刻携带的电流。两个用不同布图方案实现相同 RTL 的芯片将产生可测量的不同 EM 特征。不考虑版图几何形状的仿真无法预测攻击者的测量结果。
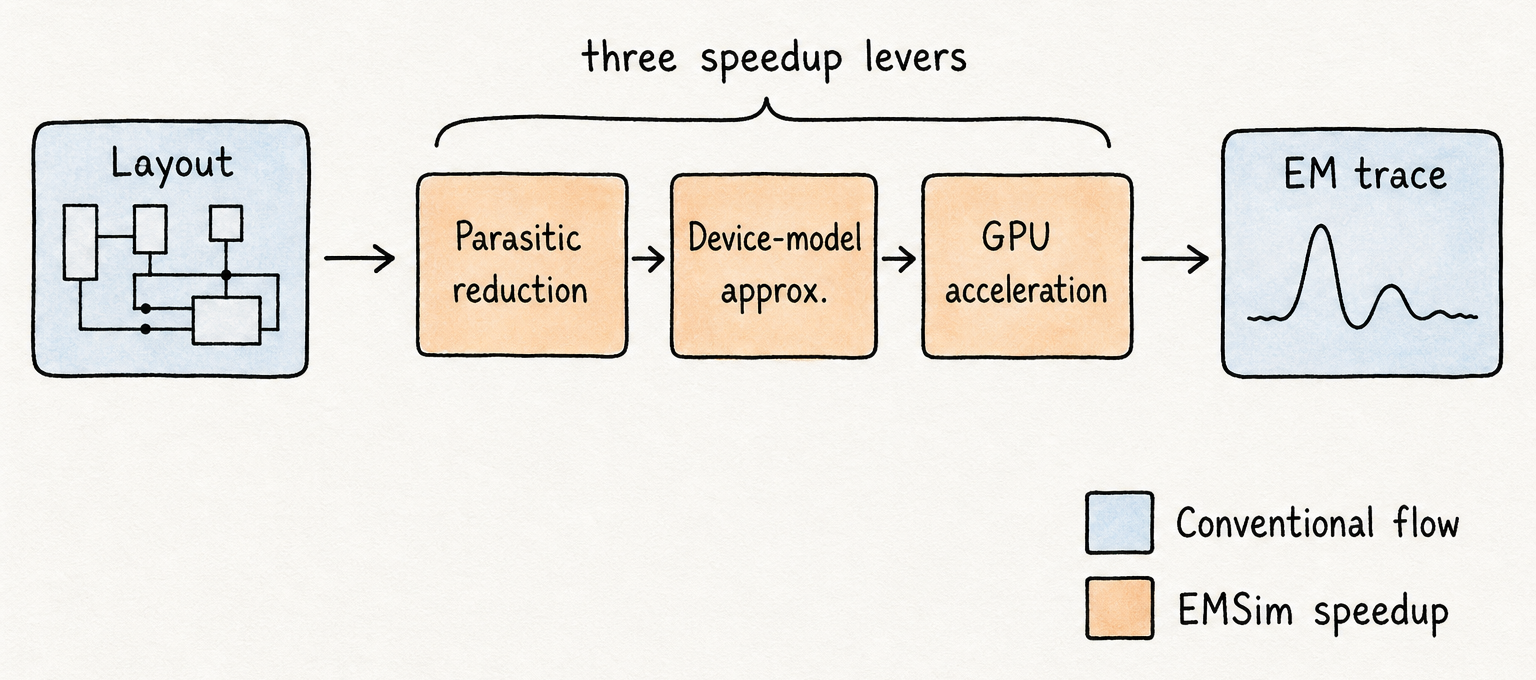
EMSim 的速度提升来自依序应用的三个手段,每个手段针对仿真流水线中的不同瓶颈。
寄生网络缩减解决第一个瓶颈:即便是适度规模模块的提取寄生网表,也可能包含数百万个 RC 节点,其中大多数对驱动 EM 辐射的集成电流波形的影响可以忽略不计。EMSim 识别并折叠那些对 EM 驱动电流贡献低于校准阈值的寄生节点,而不会实质性地改变磁场预测。缩减后的网络保留了重要节点,同时丢弃了仅用于热分析或 IR drop 分析目的而存在的节点。
器件模型近似解决第二个瓶颈:SPICE 级晶体管模型的设计目标是支持亚阈值精度、准静态分析和精确电压建立——这种保真度计算成本高,对 EM 预测基本无关紧要。EM 仿真所需要的不是准静态精度,而是集成电荷精度:有多少电荷流过某条网线,以及何时流过。EMSim 用简化的动态电流近似取代了完整晶体管模型,经过调整以匹配完整模型的集成电荷行为,代价仅为完整模型评估成本的一小部分。
GPU 加速解决第三个瓶颈。经过寄生缩减和模型近似后,仿真问题变成了一个大型稀疏线性方程组,需要在每条 trace 的每个时间步求解。这些方程组规模庞大,但对并行计算友好:使其难以在 CPU 上串行求解的结构,恰恰使其非常适合现代 GPU 上的数千个并行运算单元。将求解器迁移到 GPU,将每条 trace 的实际耗时从几分钟缩短到几秒。
版图几何形状与电流波形的相互作用驱动着上述三个手段,这一关系可以精确表达。芯片金属互连在传感器位置 r 产生的磁场为:
\[\mathbf{B}(\mathbf{r}, t) \;=\; \frac{\mu_0}{4\pi} \sum_{w} \int_{\ell_w} \frac{I_w(t)\,d\boldsymbol{\ell} \times (\mathbf{r} - \mathbf{r}')}{\|\mathbf{r} - \mathbf{r}'\|^3}\]这个公式的含义是:任意传感器位置 r 处的磁场,是每条导线电流贡献的几何加权求和。由此立即得出两个推论。首先,版图决定 EM 特征——仅凭 RTL 无法告知攻击者将测量到什么,因为积分中的几何因子是导线位置和方向的函数,而非逻辑功能。其次,精确的 EM 仿真需要精确的逐线电流波形,这正是 EMSim 三个手段所致力于高效产生的内容:缩减网络以降低求解成本,近似器件模型以降低每步计算成本,迁移到 GPU 以利用剩余的并行性。
EMSim 在中芯国际 180 nm 工艺上制造的 S-Box 和 AES 设计上进行了验证。EMSim 的内在精度——仿真信号与硅片信号的归一化互相关(NCC)——在时域达到 74%,在空域(跨探头位置)达到 98%。攻击预测准确率达到 93%:当 EMSim 标记某设计存在泄漏时,硅片测量结果有 93% 的概率与之吻合。相对基线 EDA 流程的整体仿真加速比为 32×,将单条 trace 生成时间从分钟级缩短到秒级。
EMSim+ (GAN) — learning to simulate
32× 的加速是实质性的进展,但仍然不够。可信 SCA 评估的基准——在足够统计功效下完整运行 CPA 或 TVLA 采集,以完成密钥恢复或以统计置信度认证无泄漏——需要 100K 到 1M 条 trace。EMSim 将每条 trace 的成本从几分钟降至秒级,但每条 trace 几秒乘以数百万条 trace 仍然需要数周时间。这个算术不适合设计迭代循环。物理加速移动了墙壁,但没有拆掉它。
下一个数量级的提升不可能来自对同一物理流水线的进一步调整。寄生网络缩减、器件模型近似和 GPU 并行化已经榨取了所有可获取的提升空间。问题需要的是一种完全不同形态的计算——一种一次性支付昂贵计算代价、之后每条 trace 几乎零成本的方式。
关键观察在于:物理仿真器虽然慢,但本质上是一个函数——给定芯片在某一时刻发生了什么的描述(哪些单元在切换、每个单元消耗多少电流、电流如何在电源网格和时钟树中分配),EMSim 返回芯片表面的 EM 图。这个函数是确定性的,在其输入上是平滑的。原则上,它可以被学习。
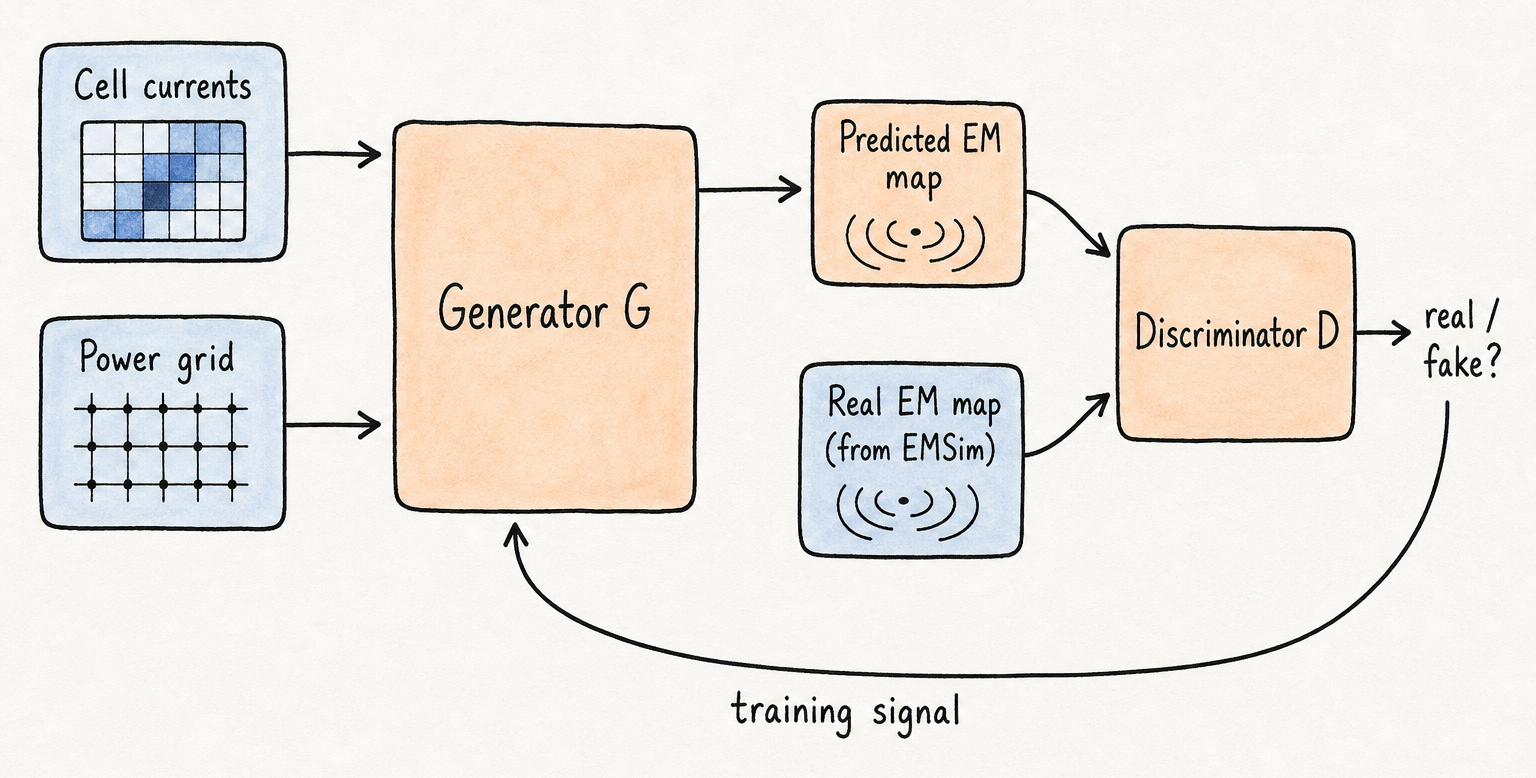
EMSim+(ICCAD 2023)将仿真重构为一个学习问题。学习模型的输入是每个时钟周期的单元电流图,以及设计的电源网格和时钟树拓扑。目标输出是芯片表面的空间 EM 辐射图——与物理仿真器计算的结果完全相同。如果学习模型能够准确再现这些输出,推理就取代了仿真,每条 trace 的成本降为通过网络的一次前向传播。
我们选择的架构是条件生成对抗网络。生成器 G 接收设计输入并生成候选 EM 图。判别器 D 接收 G 的输出或 EMSim 在相同输入下产生的真值 EM 图,并尝试区分两者。两者以对抗方式训练:G 被迫生成 D 无法与真实 EMSim 输出区分的图;D 则努力保持领先一步。对输入——单元电流和网格拓扑——的条件约束,使生成器锚定于特定设计状态,而非生成看似合理但与任何实际计算不对应的 EM 图。
训练目标将这个双人博弈形式化:
\[\min_{G}\max_{D} \; \mathbb{E}_{x,y}[\log D(x, y)] \;+\; \mathbb{E}_{x,z}[\log(1 - D(x, G(x, z)))]\]含义是:G 通过生成判别器无法与真实 EMSim 输出区分的 EM 图来取胜。其中 $x$ 是条件输入——单元电流和电源网格结构,$y$ 是该输入对应的真实 EMSim 生成 EM 图,$z$ 是允许生成器产生合理输出分布而非单一确定输出的噪声向量。对 $x$ 的条件约束使生成器锚定于实际设计,而非仅仅是一般的”EM 图”分布。
训练需要一组(输入,EMSim 真值)对的数据集,这意味着需要一次性支付 EMSim 的物理仿真成本来生成该语料库。这是正确的权衡:训练预算被分摊到之后的每条 trace 上,而一个需要 100K 条 trace 进行评估的设计,在采集结束前就能多次收回训练成本。训练完成后,推理就是一次前向传播——不需要求解微分方程,不需要稀疏线性方程组,每条 trace 不占用任何 GPU 小时。
在 1M 条 trace 的评估采集上,EMSim+ 相比 EMSim 将仿真时间缩短了 242×。基准集涵盖 Kyber、一个 AES 处理器扩展、一个掩码 AES 核心,以及一个 180 nm 硅片 AES-128。相对 EMSim 真值的精度保持在高水平,EMSim+ trace 的攻击预测与硅片测量结果的吻合率与物理仿真器一致。训练成本——每个设计一次性支付——在攻击采集超过几千条 trace 之后就已多次收回。
242× 是真实的,但针对一个设计训练的条件 GAN 只了解那一个设计——而设计迭代恰恰是快速仿真最关键的时刻。
EMSim+ (GAN+TL) — generalization across designs
GAN 带来的 242× 加速隐藏着一个只在下一次设计迭代时才会暴露的代价。训练 EMSim+ 需要一个(输入,EM 图)对的真值语料库——而生成该语料库意味着运行 EMSim 本身。对于单次评估单个设计,这是容易的权衡:一次性支付物理成本,分摊到数百万条 trace 上。对于持续迭代的设计团队——修改防护方案、更换防护措施、迁移到新工艺节点——每次变更都重置时钟。缓慢的物理步骤再次运行,然后是训练过程,快速仿真只有在两者都完成后才变得可用。这恰恰是最不应该延迟的时刻。
更深层的问题是,ICCAD 2023 的 GAN 学习的是一个设计专用函数。其权重编码了特定版图中的单元电流和电源网格拓扑如何映射到芯片表面 EM 图。这些权重对其他设计没有任何作用。每个新设计都是一个冷启动问题。
EMSim+(GAN+TL),即 TIFS 2024 扩展,通过追问 GAN 实际学到了什么来重构这一问题。生成器中的编码器实际上做了两件概念上不同的事情。它学习通用结构——版图中的电流分布产生表面 EM 场的方式、电源网格密度的作用、切换事件通过互连传播的几何形状。它同时学习设计特有的纹理:这个设计的时钟树特定空间模式、这个设计的单元放置、这个设计的电源网格布线。通用结构在同一工艺节点的不同设计中基本相同。只有设计特有的纹理发生变化。
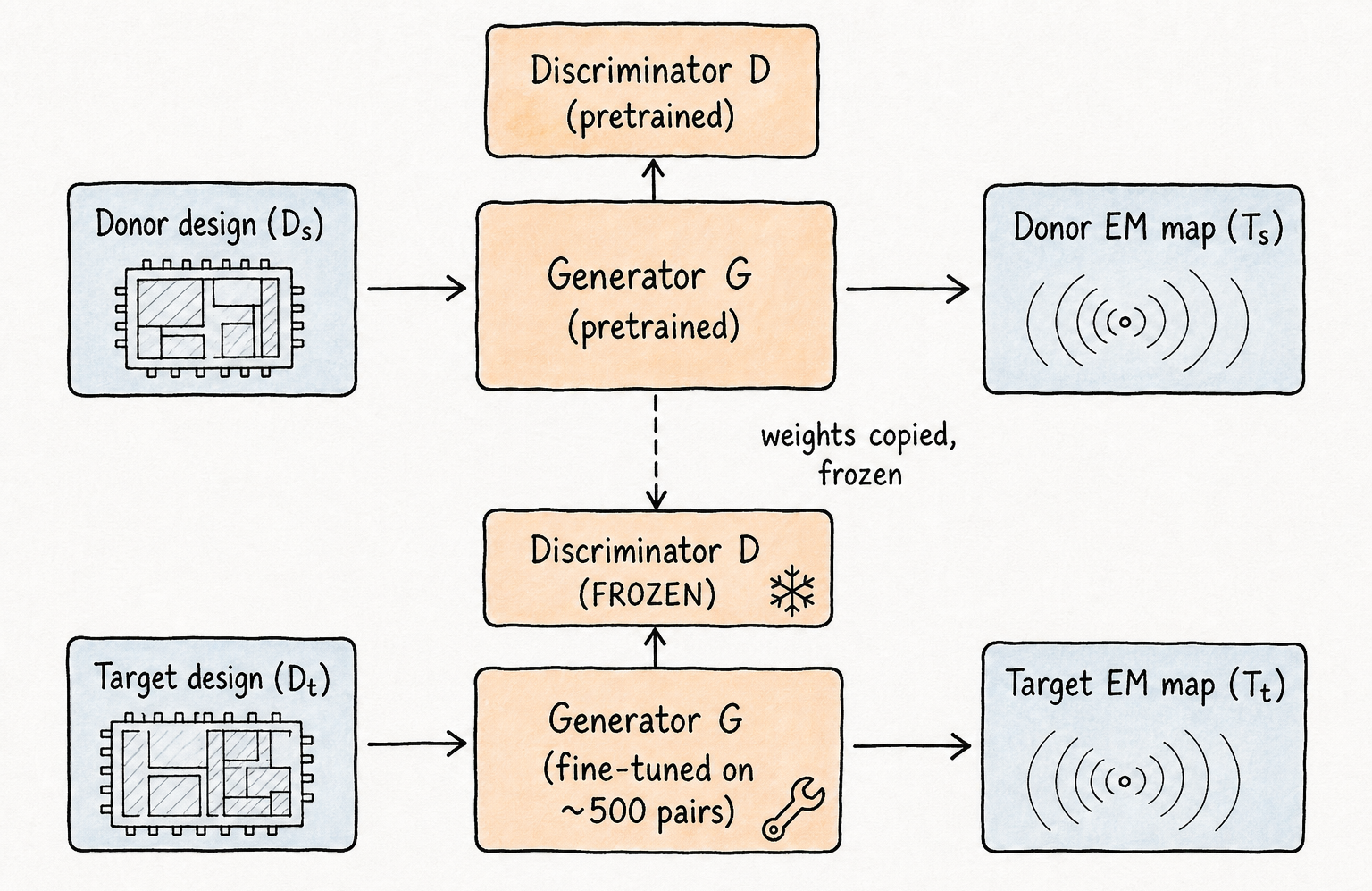
迁移学习利用了这种分离。我们在一个已用 EMSim 仿真的供体设计上预训练完整的 GAN——在我们的实验中是 AES 基准设计。训练收敛后,我们冻结判别器:它已经学会了区分真实 EM 图和生成图,这种判别信号可以迁移。对于新的目标设计,我们仅在来自该设计的小型 EMSim 语料库上微调生成器。判别器保持冻结,提供稳定的训练信号;生成器适应新设计的空间模式,同时不放弃预训练建立的共享编码器特征。
训练流水线变为:在供体设计上预训练一次,冻结判别器,在目标设计的 500 个样本对上微调生成器。500 对这个数字是迁移学习实验的关键结果——与从头训练所需的约 1,000 对相比,EMSim+(GAN+TL)将每个新设计的 EMSim 负担减半,微调的实际耗时也按比例降低。
我们在五个设计上进行了评估:180 nm 的 AES-128 基准、两个掩码 AES 变体(AES_mask_1 采用加法和乘法掩码方案,AES_mask_2 采用循环移位随机掩码方案)、带有物理电源网格保护条的 AES_pg,以及 AES_55nm——同一 AES 基准在中芯国际 55 nm CMOS 工艺下的重新实现。最后一个设计是最严峻的测试:这不仅是逻辑变化,而是完整的工艺节点迁移,其中寄生特征、单元几何形状和电流特征都发生了变化。在所有五个设计中,微调后的模型实现了超过 95% 的归一化互相关(NCC)和结构相似性(SSIM),与从头训练的模型精度相当。对微调后 trace 进行的相关电磁分析(CEMA,CPA 的 EM 类比)正确识别了受保护设计的抗侧信道性,并标记了无防护基准设计的泄漏——与硅片测量一致。
在效率方面,EMSim+(GAN+TL)保持了 GAN 的吞吐量优势。相比 EMSim,在数据集级别快 113–149×,在百万 trace 规模下快 282–483×(范围跨越五个评估设计;之前章节的 242× 基准数字是针对单个 AES-128 基准)。迁移学习的额外收益不在于每条 trace 的速度——无论权重来自预训练还是从头训练,推理成本相同——而在于降低了任何推理开始前所需的前期成本。预训练的收益分摊到之后的每个设计。在 500 对上进行微调只占一天 EMSim 计算量的一小部分。快速仿真能力几乎在新设计一出现时就变得可用,这正是真实迭代循环中最重要的特性。
在 EMSim → EMSim+ → EMSim+(GAN+TL)这条演进线索上,每一步都在 EM 通道上换取了速度或泛化能力。下一个问题关乎一个完全不同的通道。
AIPS — diffusion for power, not just EM
EMSim 和 EMSim+ 这一系列工作解决了问题 1、问题 2 和问题 3——但这三个方案都围绕 EM 通道构建。功耗是文献更丰富、攻击者社区更广泛、测量设置更简单的 SCA 通道:电源轨上的电流探头在便携性和可重复性上优于近场 EM 探头。任何止步于 EM 的设计评估框架,至少是不完整的。
功耗侧还存在一个 EM 侧没有的工具缺口。Synopsys PrimeTime PX(PTPX)是数字设计流程中瞬态功耗仿真的事实标准参考工具。它准确、经过充分的硅片验证,是设计团队需要真值时最信赖的结果。它也是任何现代流片前 SCA 评估中最慢的步骤:PTPX 是为回答热设计和电压变化问题而构建的,这些问题关心的是每个时钟周期的平均功耗。SCA 攻击不同。它们利用纳秒级瞬态波形——编码各个逻辑路径上数据相关切换活动的瞬态电流尖峰——而非长窗口平均值。现有的为热感知布图和 IR drop 分析而开发的 AI 功耗估算工具工作在平均功耗体制下。它们快速、有用,但输出缺乏相关功耗分析实际攻击所需的细粒度时间结构。差距:针对流片前 SCA 评估的快速、精确、纳秒分辨率瞬态功耗仿真。
AIPS(TCHES 2026)是我们对问题 4 的回答。它同时跨越两个边界:从 EM 通道到功耗通道,以及从 EMSim+ 中使用的 GAN 架构到以扩散模型作为生成骨干。重新审视架构的选择是经过深思熟虑的,这对于理解 AIPS 为何能泛化到我们评估的广泛设计至关重要。
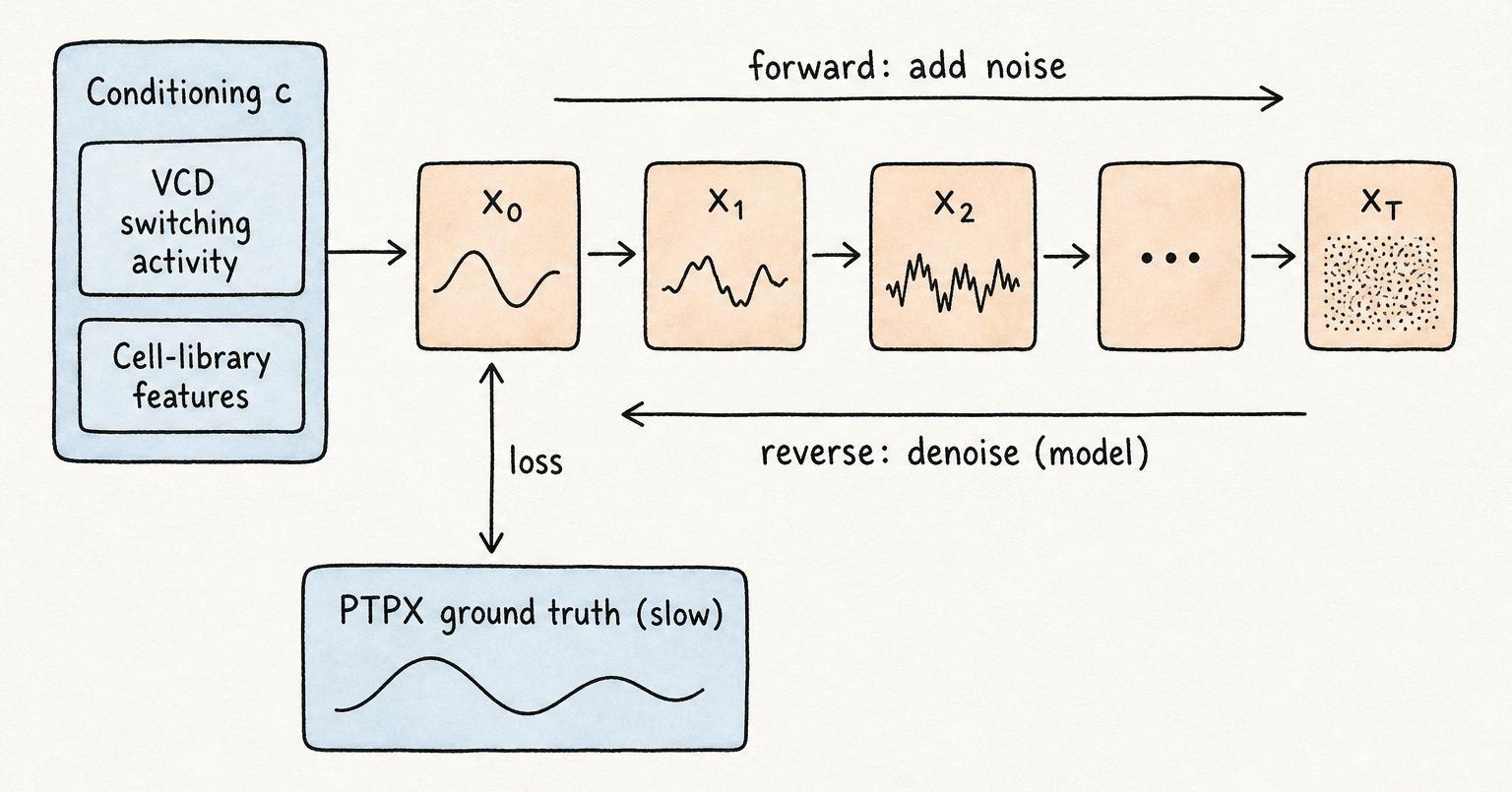
AIPS 的训练数据是由 PTPX 生成的功耗轨迹语料库——即慢速、精确的真值。告知模型芯片内部发生了什么的条件信号,由两个来源构建:从设计的 VCD(值变化转储,value change dump)中提取的每周期切换活动,记录哪些单元在每个时钟沿改变状态;以及捕获标准单元库中每种单元类型时序和功耗特性的工艺库特征。这两者共同描述了芯片按周期计算的内容,以模型可以学习并映射到瞬态功耗波形的方式表达。输出是纳秒分辨率下任意长度的时序 trace——与 PTPX 产生的格式相同,但以推理成本而非仿真成本生成。
从 GAN 转向扩散并非偶然。条件 GAN 通过欺骗判别器来学习;其训练信号是对抗性的,这在平均情况下能产生出色的质量,但可能导致模式崩溃——生成器固定在满足判别器的狭窄输出范围内,却未能覆盖真实芯片会产生的完整 trace 分布。对于 SCA 评估,模式崩溃是危险的:如果合成 trace 全都看起来相似,统计攻击采集就失去了平均化噪声所需的 trace 多样性,无法达到可靠结论。扩散模型学习逐步去噪:它们被训练为逆转一个在多个步骤中向 trace 添加高斯噪声的前向过程,推理时从纯噪声反向运行该过程到干净的 trace。这种形式自然支持多样化输出——不同噪声种子产生统计独立的 trace——同时条件约束将每个输出锚定于工作负载。
条件反向扩散步骤为:
\[p_\theta(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{c}) \;=\; \mathcal{N}\!\left(\boldsymbol{\mu}_\theta(\mathbf{x}_t, t, \mathbf{c}),\; \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t, \mathbf{c})\right)\]含义是:在每个去噪步骤中,模型预测更干净 trace 的高斯分布,以工作负载 $\mathbf{c}$ 为条件。运行链 $T$ 步,便得到一条在分布上与 PTPX 匹配的合成瞬态 trace。新噪声种子 → 新 trace;相同 $\mathbf{c}$ → 相同工作负载;在任意规模攻击采集中保持统计一致性。
效率表现分为两种模式。在推理阶段——训练完成后——生成一条 trace 只需通过扩散采样器的前向传播:新噪声种子输入,新 trace 输出,无需调用 PTPX。这种纯推理模式提供最大的绝对加速比。即便将完整训练成本分摊进来,该框架在 SCA 采集实际运行的 100K–1M trace 规模下仍具优势——以下具体数字量化了这一点。
我们在五个目标上评估了 AIPS,这些目标的选择旨在覆盖设计团队可能需要评估的实际范围:
- AES(基准密码,无掩码)
- Kyber(NIST 选定的后量子密钥封装机制)
- 两种掩码 AES 变体(测试高阶 SCA,其中防护措施主动使泄漏复杂化)
- RISC-V 核心(通用处理器执行 AES,而非专用密码模块)
在所有五个目标上,AIPS trace 在波形相似度指标下与 PTPX 真值吻合,并复现了相同的 SCA 评估结论——一阶攻击下相同的密钥恢复结果,以及存在掩码时相同的高阶泄漏评估。在效率方面:
- 在 1M trace 下比 PTPX 快 4–42×(含训练成本;精确数字见下方对比表)
- 训练摊销后每条 trace 加速比高达 10⁴×
- 约 1K 条训练 trace 即可达到完整精度——PTPX 可在可接受的时间内生成的语料库规模
- 吞吐量优势随 trace 长度增加而复合增长
纵观四篇论文,每一步都换取了不同维度的能力提升。下一节将它们作为一个统一设计空间来解读。
What changed across the lineage
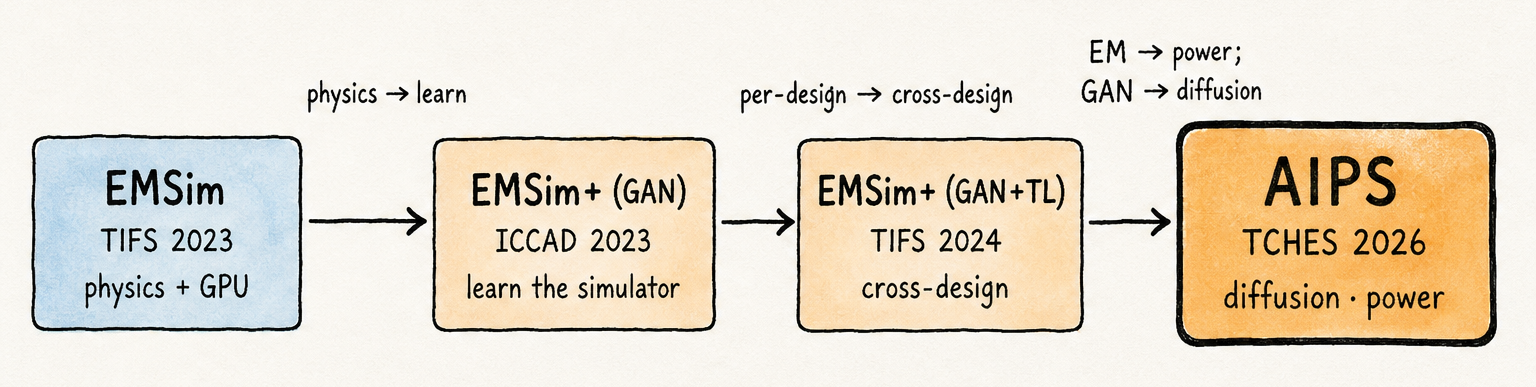
将这条演进线索展开为单一图示,便揭示了每篇独立论文都未明确陈述的内容:每一步换取了不同维度的能力,而每一步固有的局限,恰恰是下一步的动因。
第一次转变——从物理到学习——通过以一次性训练语料库换取每条 trace 的仿真成本,将吞吐量上限提升了一个数量级。
第二次转变——从单设计到跨设计——将该学习型仿真器的启动成本降低到在几百对上进行微调,使快速仿真在设计迭代开始时就能可用,而不必等到结束。
第三次转变——从 EM 到功耗,同步将骨干从 GAN 换为扩散——开辟了第二个通道,并以一种自然支持功耗侧 SCA 评估所需 trace 多样性的训练目标取代了对抗性训练目标。
纵观这些步骤:速度、泛化能力、覆盖广度——每步获得一个维度,每步将下一个维度留给后续论文。
| Paper | Channel | Backbone | Generalization | Training data | Speedup vs. ground truth | Validated on |
|---|---|---|---|---|---|---|
| EMSim | EM | physics + parasitic reduction + GPU | per design | n/a | 32× over baseline | S-Box, AES (SMIC 180 nm silicon) |
| EMSim+ (GAN) | EM | conditional GAN | per design | ~1K pairs (per design) | 242× over EMSim at 1M traces | Kyber + 3 AES variants (extension, masked, 180 nm silicon) |
| EMSim+ (GAN+TL) | EM | GAN + transfer learning | cross-design + cross-node | ~500 fine-tune pairs | 113–149× per-dataset; 282–483× at 1M-trace scale | 5 designs, 180 nm + 55 nm |
| AIPS | Power | conditional diffusion | multi-target (5 designs) | ~1K traces | 4.14–42.44× over PTPX; up to 10⁴× inference-only | AES, Kyber, masked AES (×2), RISC-V |
这条演进线索的结构很重要,因为它排除了一种更简单的解读。这不是四次针对同一问题的尝试,每次都快一点。EMSim 回答了:物理精确的 EM 仿真能否在评估规模下运行?EMSim+(GAN)回答了:学习模型能否取代每条 trace 的物理仿真?EMSim+(GAN+TL)回答了:该学习模型能否在设计之间复用而无需从头开始?AIPS 回答了:不同的生成架构能否将这一方法扩展到功耗通道,同时保留该通道所需的 trace 多样性?每个问题只有在上一个答案让它变得具体后才变得可见。这条演进线索是一系列依次解决的具体瓶颈,而非朝向单一目标效率数字的进展。
这是本文的核心论断,直白地说:流片前 SCA 评估不是一个问题,而是一族问题。
Open problems
掩码和后量子密码(PQC)设计的规模化评估。 AIPS 已经评估了 Kyber 和两个掩码 AES 变体,但更高阶掩码——三阶及以上——以及更大型的 PQC 方案(如 Dilithium 风格签名、Falcon 和完整混合 TLS 协议栈)对任何仿真框架都提出了不同的要求。稀有泄漏事件变得更加稀有,训练数据需求随设计复杂度增长,而密码核周围的 SoC 上下文引入了仅针对密码模块的评估可能遗漏的切换活动。随着设计规模的扩大,扩散模型的每条 trace 成本变得更加重要,而非更不重要——采集规模随设计增长,因此吞吐量的任何回退都会复合放大。
形成防护措施综合的闭环。 评估告诉你泄漏在哪里;防护告诉你如何修复。在仿真中识别出泄漏的网线或路径,只有在每次候选修复后无需重新运行完整评估周期才有实际意义。PathFinder(DAC 2022 · PDF)和 Formal Path(TECS 2025 · PDF)——我们在自动泄漏路径识别和逻辑级混淆方面的工作——是我们对这个防护环路的探索。未来的一篇文章将以与本文介绍评估系列同等的深度来介绍它们。
Code
-
github.com/jinyier/EMSim— EMSim and EMSim+ implementations. -
github.com/jinyier/AIPS— AIPS implementation.
References
- H. Ma, M. Panoff, J. He, Y. Zhao, Y. Jin. EMSim: A Fast Layout Level Electromagnetic Emanation Simulation Framework for High Accuracy Pre-Silicon Verification. IEEE Transactions on Information Forensics and Security, 2023. PDF
- Y. Gao, H. Ma, J. Kong, J. He, Y. Zhao, Y. Jin. EMSim+: Accelerating Electromagnetic Security Evaluation with Generative Adversarial Network. IEEE/ACM ICCAD, 2023. PDF
- Y. Gao, H. Ma, Q. Zhang, X. Song, Y. Jin, J. He, Y. Zhao. EMSim+: Accelerating Electromagnetic Security Evaluation With Generative Adversarial Network and Transfer Learning. IEEE Transactions on Information Forensics and Security, 2024. PDF
- Y. Gao, H. Ma, T. Zhang, J. He, Y. Zhao, M. Stojilović, Y. Jin. AIPS: AI-Based Power Simulation for Pre-Silicon Side-Channel Security Evaluation. IACR Transactions on Cryptographic Hardware and Embedded Systems, 2026. PDF
- H. Ma. Research on Pre-Silicon Security Evaluation and Protection Techniques for Cryptographic Chip. Ph.D. Thesis, Tianjin University, 2023. PDF